Importing from Different Data Sources
We can construct a DataFrame from a variety of data sources. The most common data sources are:
- CSV files
- Excel files
- SQL databases
- JSON files
- HTML files
In this notes, we see some of those examples in action
📥 From CSV
import pandas as pd
import numpy as np
url = "https://raw.github.com/pandas-dev/pandas/main/pandas/tests/io/data/csv/tips.csv"
tips = pd.read_csv(url)
tips.head()
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
The .head() function gets you the first 5 elements of the data frame to show what the data would look like.
You could also use the function describe() which return summary statistics about the dataset
tips.describe()
| total_bill | tip | size | |
|---|---|---|---|
| count | 244.000000 | 244.000000 | 244.000000 |
| mean | 19.785943 | 2.998279 | 2.569672 |
| std | 8.902412 | 1.383638 | 0.951100 |
| min | 3.070000 | 1.000000 | 1.000000 |
| 25% | 13.347500 | 2.000000 | 2.000000 |
| 50% | 17.795000 | 2.900000 | 2.000000 |
| 75% | 24.127500 | 3.562500 | 3.000000 |
| max | 50.810000 | 10.000000 | 6.000000 |
Downloading Dataset from Kaggle using OpenDatasets
In cases where you're trying to use datasets that are available on online sources like Kaggle. You can continue to use the URL directly, if the source makes one available. Or you could use a tool such as opendatasets.
opendatasets is a Python library for downloading datasets from online sources like Kaggle and Google Drive using a simple Python command.
The following examples show how you can (DOWNLOAD) the US Elections Dataset available via Kaggle. You will be asked to provide your username and authentication API key (that's not the same as your account password).
To get your Kaggle API Key:
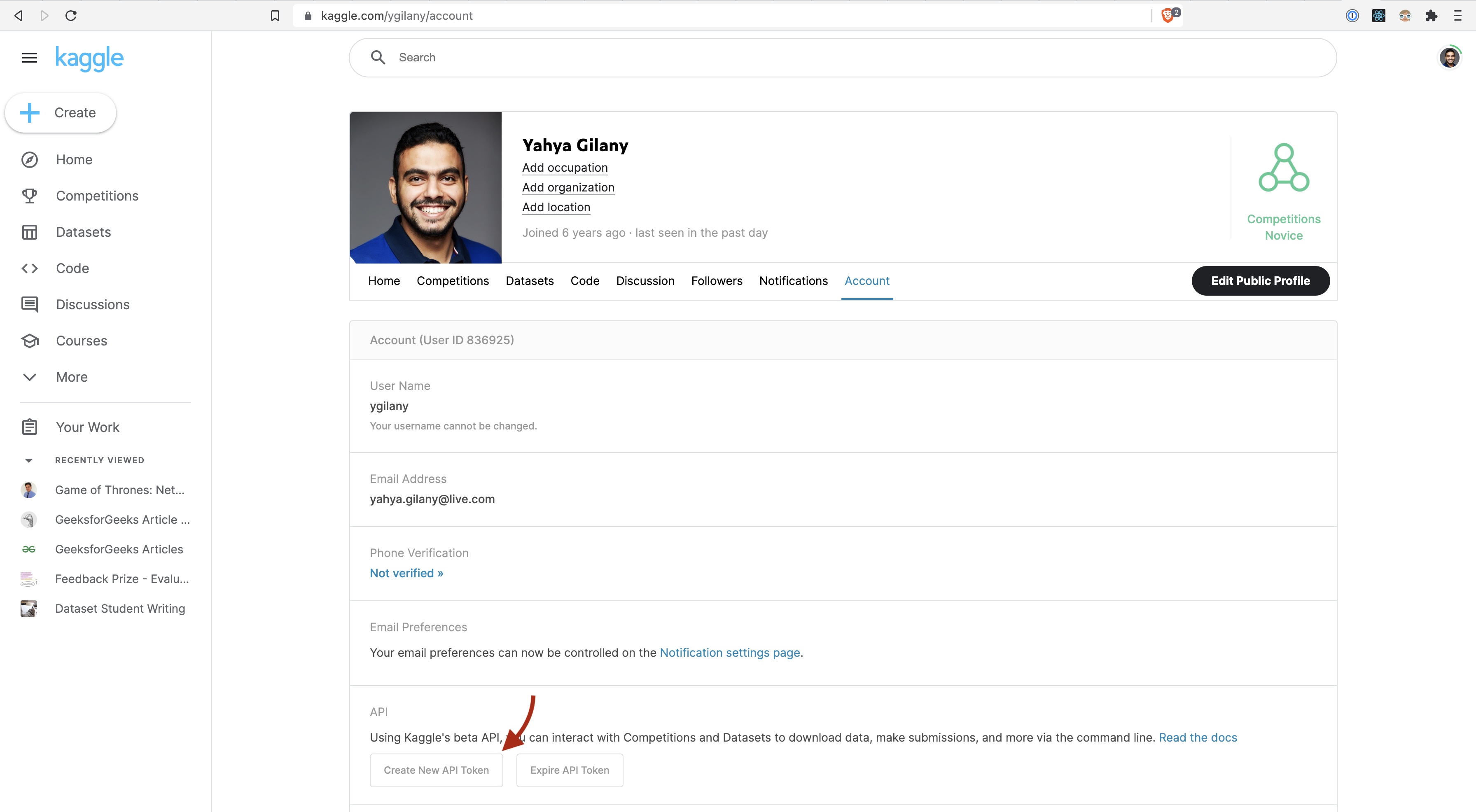
this will download a file named kaggle.json that contains your account name and a key that you'll use to authenticate in the following code cell.
import opendatasets as od
dataset_url = 'https://www.kaggle.com/tunguz/us-elections-dataset'
od.download(dataset_url, data_dir='./data')
Once downloaded, you can Import the CSV file into a data frame.
## import CSv file from local folder into a dataframe
elections = pd.read_csv('./data/us-elections-dataset/1976-2020-president.csv')
elections.head()
| year | state | state_po | state_fips | state_cen | state_ic | office | candidate | party_detailed | writein | candidatevotes | totalvotes | version | notes | party_simplified | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1976 | ALABAMA | AL | 1 | 63 | 41 | US PRESIDENT | CARTER, JIMMY | DEMOCRAT | False | 659170 | 1182850 | 20210113 | NaN | DEMOCRAT |
| 1 | 1976 | ALABAMA | AL | 1 | 63 | 41 | US PRESIDENT | FORD, GERALD | REPUBLICAN | False | 504070 | 1182850 | 20210113 | NaN | REPUBLICAN |
| 2 | 1976 | ALABAMA | AL | 1 | 63 | 41 | US PRESIDENT | MADDOX, LESTER | AMERICAN INDEPENDENT PARTY | False | 9198 | 1182850 | 20210113 | NaN | OTHER |
| 3 | 1976 | ALABAMA | AL | 1 | 63 | 41 | US PRESIDENT | BUBAR, BENJAMIN ""BEN"" | PROHIBITION | False | 6669 | 1182850 | 20210113 | NaN | OTHER |
| 4 | 1976 | ALABAMA | AL | 1 | 63 | 41 | US PRESIDENT | HALL, GUS | COMMUNIST PARTY USE | False | 1954 | 1182850 | 20210113 | NaN | OTHER |
📥 From API
To import data using an HTTP API in Python, you have multiple options for the HTTP client libraries. The one I choose and use here is requests. Here I will show you how you can use requests to query data from the US Census Data, and from the John Hopkins COVID APIs.
The most basic example is the following:
import requests
x = requests.get('https://w3schools.com/python/demopage.htm')
print(x.text)
However, depending on the API provider, we may need to pass additional configurations and options in the request. We'll see that in the following examples
US Census Data
The US Census Bureau provides machine-readable dataset via a developer API.
Developers could use the statistics available through this API to create apps that:
- Show commuting patterns for every city in America.
- Display the latest numbers on owners and renters in a neighborhood someone may want to live in.
- Provide a local government a range of socioeconomic statistics on its population.
Here are some of the datasets available that you can use
Each dataset provides technical documentation for the different variables you could get from that Particular API. Here's an example
To construct a request with requests we need to determine the URL we need to send the request to.
import requests
HOST = "https://api.census.gov/data"
year = "2022"
dataset = "cps/basic/apr"
base_url = "/".join([HOST, year, dataset]) # JOIN the variables with a `/` separator https://api.census.gov/data/2022/cps/basic/apr
# The dataset is huge and contains a lot of data, so we'll request a subset of the available variables.
dataset_variables = ["GEDIV","HRMIS","PENATVTY"]
predicates = {}
predicates["get"] = ",".join(dataset_variables) # JOIN the variables with a `,` separator
predicates["for"] = "state:*"
response = requests.get(base_url, params=predicates)
census_data = pd.DataFrame.from_records(response.json()[1:], columns=response.json()[0])
print(census_data.head())
This link here describes what those variables mean.
Also, you note that even the states are presented with some numerical values. to get the values of those state IDs, I'll send another request to another dataset
import requests
HOST = "https://api.census.gov/data"
year = "2017"
dataset = "acs/acs5"
base_url = "/".join([HOST, year, dataset]) # JOIN the variables with a `/` separator https://api.census.gov/data/2022/cps/basic/apr
dataset_variables = ["NAME"]
predicates = {}
predicates["get"] = ",".join(dataset_variables)
predicates["for"] = "state:*"
r = requests.get(base_url, params=predicates)
states = pd.DataFrame.from_records(r.json()[1:], columns=r.json()[0])
print(states.head())
You could subset the data recieved to find the State Numerical Code for the Ohio
# Find the state code with the name "Ohio"
print(states[states["NAME"] == "Ohio"])
or you could just combine and merge the 2 data sets on the state ID, so we end up with a single dataset with all the information we need.
# Merge census_data and states
full_census_data = pd.merge(census_data, states, on="state")
full_census_data.head() # Print the first 5 rows
| GEDIV | HRMIS | PENATVTY | state | NAME | |
|---|---|---|---|---|---|
| 0 | 7 | 6 | 57 | 40 | Oklahoma |
| 1 | 7 | 6 | 57 | 40 | Oklahoma |
| 2 | 7 | 6 | 57 | 40 | Oklahoma |
| 3 | 7 | 6 | 57 | 40 | Oklahoma |
| 4 | 7 | 3 | 57 | 40 | Oklahoma |
John Hopkins Covid API
John Hopkins University | Cornoavirus Resources Center have been collecting and publishing data regarding COVID-19 since day one. You can learn more about that and find official resources for how to use the data here
I believe someone is publishing those datasets by means of API through the RapidAPI platform. Whether it's an official resource or not, the goal of this exercise is to show you how to work with APIs in general.
You can see a very easy to understand documentation of how to use the API here.
import os
from dotenv import load_dotenv
import requests
load_dotenv(override=True)
rapid_api_key = os.getenv("RAPID_API_KEY")
url = "https://covid-19-statistics.p.rapidapi.com/reports"
querystring = {"region_province":"Ohio","iso":"USA","region_name":"US","q":"US Ohio","date":"2020-04-16"}
headers = {
"X-RapidAPI-Key": rapid_api_key,
"X-RapidAPI-Host": "covid-19-statistics.p.rapidapi.com"
}
response = requests.request("GET", url, headers=headers, params=querystring)
# save json result into a pandas dataframe
covid_data = pd.DataFrame(response.json()["data"][0]["region"]["cities"])
covid_data.head()
| name | date | fips | lat | long | confirmed | deaths | confirmed_diff | deaths_diff | last_update | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Adams | 2020-04-16 | 39001 | 38.84541072 | -83.4718964 | 3 | 0 | 0 | 0 | 2020-04-16 23:30:51 |
| 1 | Allen | 2020-04-16 | 39003 | 40.77285242 | -84.10802343 | 57 | 6 | 6 | 2 | 2020-04-16 23:30:51 |
| 2 | Ashland | 2020-04-16 | 39005 | 40.84772277 | -82.27280781 | 5 | 0 | -1 | 0 | 2020-04-16 23:30:51 |
| 3 | Ashtabula | 2020-04-16 | 39007 | 41.70860332 | -80.74830218 | 45 | 3 | 9 | 0 | 2020-04-16 23:30:51 |
| 4 | Athens | 2020-04-16 | 39009 | 39.33425634 | -82.04278644 | 3 | 1 | 0 | 0 | 2020-04-16 23:30:51 |
📥 Using Socrata
The Socrata Open Data API allows you to programmatically access a wealth of open data resources from governments, non-profits, and NGOs around the world.
Cincinnati Datasets
For example, here are a bunch of datasets that you can find about the City of Cincinnati
For you to be able to access any of those datasets, you need to register to get an application token.
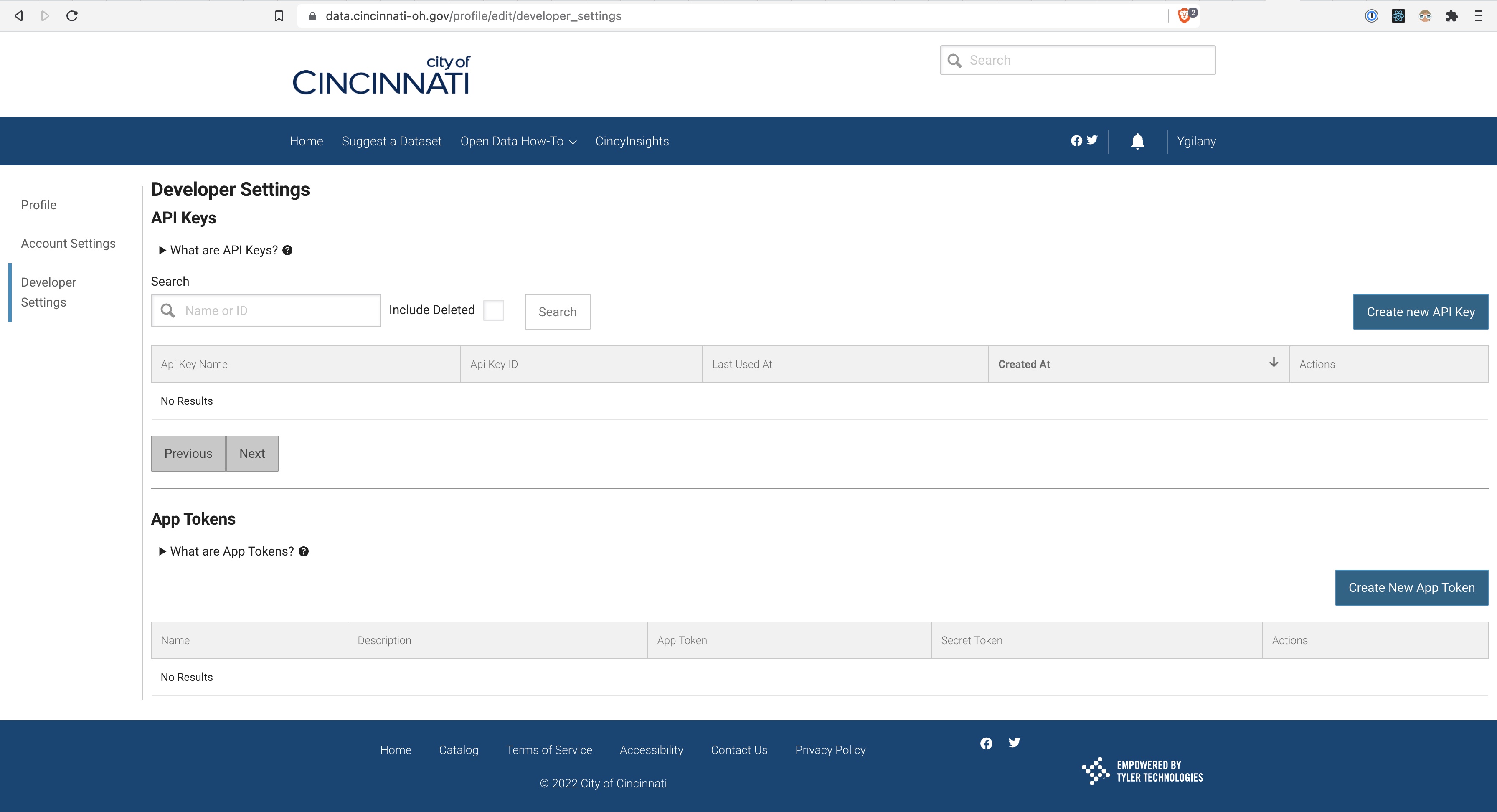
import os
from dotenv import load_dotenv
import pandas as pd
from sodapy import Socrata
load_dotenv(override=True)
# Example authenticated client (needed for non-public datasets):
app_token = os.getenv("SODA_APP_TOKEN")
# client = Socrata("data.cincinnati-oh.gov", None)
client = Socrata("data.cincinnati-oh.gov",app_token)
# First 2000 results, returned as JSON from API / converted to Python list of
# dictionaries by sodapy.
results = client.get("rvmt-pkmq", limit=2000)
# Convert to pandas DataFrame
results_df = pd.DataFrame.from_records(results)
print(results_df.columns)
📥 From SQL
About SQL
SQL is a powerful programming language that allows us to interact and save data in Relational Databases. SQL stores data in a table format, consisting of rows representing a number of records and columns corresponding to various features.
There are many categories categories of SQL commands:
Data Definition Language (DDL)
CREATE,ALTER,DROP; these are the commands used to define the data structure or the data model.
Data Manipulation Language (DML)
INSERT,UPDATE,DELETE; these are the commands used to modify data in existing databases.
Data Query Language (DQL)
SELECT
Data Control Langauge (DCL)
GRANT,REVOKE; administrative commands to manage user permissions and access
Transaction Control Language (TCL)
COMMIT,ROLLBACK,BEGIN TRANSACTION; for managing transaction queries where multiple DML are processed in a single operation. This is more for software developers than it is for data analysts.
While there is a SQL Standard, there are many dialects and implementations of that standard. You'll often hear of Microsoft SQL Server, MySQL, PostgreSQL, ...etc. All of these require that the an instance of the server is hosted on some server or locally.
Another dialect of SQL is called SQLite. This is a small, self-contained, serverless relational database system. This means that the entire database would be contained in a file. that can be shared with others. This has pros and cons.
For the purposes of demo-ing how we can use Python to interact with SQL Database, I'm using a sample SQLite database. The SQLite Tutorial Website offers same sample database for testing and training.
I'm here demo-ing using the Chinook database in python. This is the database schema for the database tables.
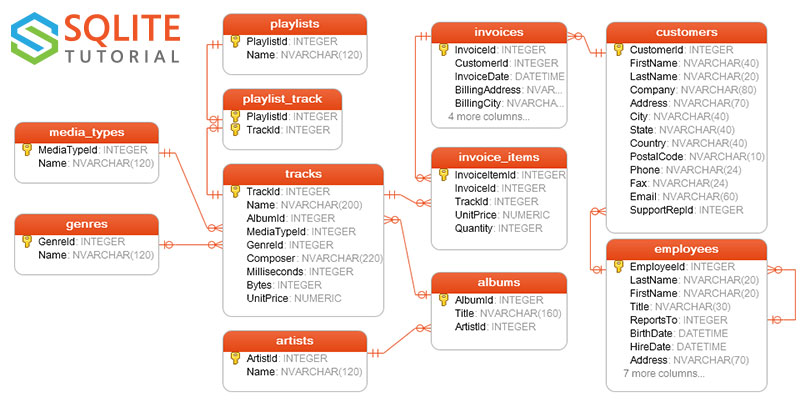
First off, I'll download the sqlite database from https://www.sqlitetutorial.net/wp-content/uploads/2018/03/chinook.zip. The downloaded file is zipped so I will need to also unzip that file. (of course we can do that manually, but how savage is that)
from zipfile import ZipFile
from urllib.request import urlretrieve
file_handle, _ = urlretrieve("https://www.sqlitetutorial.net/wp-content/uploads/2018/03/chinook.zip")
zipfile = ZipFile(file_handle, 'r')
zipfile.extractall(".")
zipfile.close()
We'll need to use the SQLAlchemy package from the Python Package Index.
Here we define the connection string a sqlite connection to a locally available SQLite Database file chinook
from sqlalchemy import create_engine
connection_string = "sqlite:///chinook.db"
engine = create_engine(connection_string)
dbConnection = engine.connect()
import pandas as pd
genres_df = pd.read_sql("SELECT * FROM genres;", dbConnection)
genres_df
| GenreId | Name | |
|---|---|---|
| 0 | 1 | Rock |
| 1 | 2 | Jazz |
| 2 | 3 | Metal |
| 3 | 4 | Alternative & Punk |
| 4 | 5 | Rock And Roll |
| 5 | 6 | Blues |
| 6 | 7 | Latin |
| 7 | 8 | Reggae |
| 8 | 9 | Pop |
| 9 | 10 | Soundtrack |
| 10 | 11 | Bossa Nova |
| 11 | 12 | Easy Listening |
| 12 | 13 | Heavy Metal |
| 13 | 14 | R&B/Soul |
| 14 | 15 | Electronica/Dance |
| 15 | 16 | World |
| 16 | 17 | Hip Hop/Rap |
| 17 | 18 | Science Fiction |
| 18 | 19 | TV Shows |
| 19 | 20 | Sci Fi & Fantasy |
| 20 | 21 | Drama |
| 21 | 22 | Comedy |
| 22 | 23 | Alternative |
| 23 | 24 | Classical |
| 24 | 25 | Opera |
Let's add one item to the dataframe
genres_df = pd.concat([genres_df, pd.DataFrame.from_records([{'GenreId': '26', 'Name': 'Arabic Pop'}])], ignore_index=True)
genres_df
| GenreId | Name | |
|---|---|---|
| 0 | 1 | Rock |
| 1 | 2 | Jazz |
| 2 | 3 | Metal |
| 3 | 4 | Alternative & Punk |
| 4 | 5 | Rock And Roll |
| 5 | 6 | Blues |
| 6 | 7 | Latin |
| 7 | 8 | Reggae |
| 8 | 9 | Pop |
| 9 | 10 | Soundtrack |
| 10 | 11 | Bossa Nova |
| 11 | 12 | Easy Listening |
| 12 | 13 | Heavy Metal |
| 13 | 14 | R&B/Soul |
| 14 | 15 | Electronica/Dance |
| 15 | 16 | World |
| 16 | 17 | Hip Hop/Rap |
| 17 | 18 | Science Fiction |
| 18 | 19 | TV Shows |
| 19 | 20 | Sci Fi & Fantasy |
| 20 | 21 | Drama |
| 21 | 22 | Comedy |
| 22 | 23 | Alternative |
| 23 | 24 | Classical |
| 24 | 25 | Opera |
| 25 | 26 | Arabic Pop |
Let's update the database with the new data
genres_df.to_sql('genres', dbConnection, if_exists='replace', index=False)
Let's see what's in the database table now
df2 = pd.read_sql("SELECT * FROM genres;", dbConnection)
df2
| GenreId | Name | |
|---|---|---|
| 0 | 1 | Rock |
| 1 | 2 | Jazz |
| 2 | 3 | Metal |
| 3 | 4 | Alternative & Punk |
| 4 | 5 | Rock And Roll |
| 5 | 6 | Blues |
| 6 | 7 | Latin |
| 7 | 8 | Reggae |
| 8 | 9 | Pop |
| 9 | 10 | Soundtrack |
| 10 | 11 | Bossa Nova |
| 11 | 12 | Easy Listening |
| 12 | 13 | Heavy Metal |
| 13 | 14 | R&B/Soul |
| 14 | 15 | Electronica/Dance |
| 15 | 16 | World |
| 16 | 17 | Hip Hop/Rap |
| 17 | 18 | Science Fiction |
| 18 | 19 | TV Shows |
| 19 | 20 | Sci Fi & Fantasy |
| 20 | 21 | Drama |
| 21 | 22 | Comedy |
| 22 | 23 | Alternative |
| 23 | 24 | Classical |
| 24 | 25 | Opera |
| 25 | 26 | Arabic Pop |
📥 From MongoDB
If you've taken Contemporary Database, you have already learned about One of the NoSQL Database options, MongoDB.
In the following example, I will show you how you can use Python to Query Data from a MongoDB.
Here we'll need to install the PyMongo Package. Depending on the MongoDB instance you're trying to connect to, you will need an extra companion package. You can find out about that in this link to the PyMongo Documentation. For instances:
- For AWS, you need to install
pymongo[aws] - For
mongodb+srvconnection strings, you'd need to installpymongo[srv]
For the MongoDB instance on Mongo Atlas, we need pymongo[srv], pipenv install 'pymongo[srv]'
import pandas as pd
from pymongo import MongoClient
import os
from dotenv import load_dotenv
load_dotenv(override=True)
pd.set_option('display.max_columns', None) # Otherwise, pandas would not be able to display the full content of each cell
def _connect_mongo(host, username, password, db):
""" A util for making a connection to mongo """
mongo_uri = 'mongodb+srv://%s:%s@%s/?retryWrites=true&w=majority"' % (username, password, host)
conn = MongoClient(mongo_uri)
return conn[db]
def read_mongo(db, collection, query={}, no_id=True):
""" Read from Mongo and Store into DataFrame """
# Make a query to the specific DB and Collection
cursor = db[collection].find(query)
# Expand the cursor and construct the DataFrame
df = pd.DataFrame(list(cursor))
# Delete the _id
if no_id:
del df['_id']
return df
username = os.getenv("MONGO_USERNAME")
password = os.getenv("MONGO_PASSWORD")
db = _connect_mongo(host='it4063c.ykv1yjn.mongodb.net', username=username, password=password, db='sample_airbnb')
df = read_mongo(db=db, collection='listingsAndReviews', query={'bedrooms': {'$lt': 2}}, no_id=False)
df.head()
| _id | listing_url | name | summary | space | description | neighborhood_overview | notes | transit | access | interaction | house_rules | property_type | room_type | bed_type | minimum_nights | maximum_nights | cancellation_policy | last_scraped | calendar_last_scraped | accommodates | bedrooms | beds | number_of_reviews | bathrooms | amenities | price | weekly_price | monthly_price | cleaning_fee | extra_people | guests_included | images | host | address | availability | review_scores | reviews | first_review | last_review | security_deposit | reviews_per_month | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10009999 | https://www.airbnb.com/rooms/10009999 | Horto flat with small garden | One bedroom + sofa-bed in quiet and bucolic ne... | Lovely one bedroom + sofa-bed in the living ro... | One bedroom + sofa-bed in quiet and bucolic ne... | This charming ground floor flat is located in ... | There´s a table in the living room now, that d... | Easy access to transport (bus, taxi, car) and ... | I´ll be happy to help you with any doubts, tip... | I just hope the guests treat the space as they... | Apartment | Entire home/apt | Real Bed | 2 | 1125 | flexible | 2019-02-11 05:00:00 | 2019-02-11 05:00:00 | 4 | 1 | 2.0 | 0 | 1.0 | [Wifi, Wheelchair accessible, Kitchen, Free pa... | 317.00 | 1492.00 | 4849.00 | 187.00 | 0.00 | 1 | {'thumbnail_url': '', 'medium_url': '', 'pictu... | {'host_id': '1282196', 'host_url': 'https://ww... | {'street': 'Rio de Janeiro, Rio de Janeiro, Br... | {'availability_30': 0, 'availability_60': 0, '... | {} | [] | NaT | NaT | NaN | NaN | |
| 1 | 1001265 | https://www.airbnb.com/rooms/1001265 | Ocean View Waikiki Marina w/prkg | A short distance from Honolulu's billion dolla... | Great studio located on Ala Moana across the s... | A short distance from Honolulu's billion dolla... | You can breath ocean as well as aloha. | Honolulu does have a very good air conditioned... | Pool, hot tub and tennis | We try our best at creating, simple responsive... | The general welfare and well being of all the ... | Condominium | Entire home/apt | Real Bed | 3 | 365 | strict_14_with_grace_period | 2019-03-06 05:00:00 | 2019-03-06 05:00:00 | 2 | 1 | 1.0 | 96 | 1.0 | [TV, Cable TV, Wifi, Air conditioning, Pool, K... | 115.00 | 650.00 | 2150.00 | 100.00 | 0.00 | 1 | {'thumbnail_url': '', 'medium_url': '', 'pictu... | {'host_id': '5448114', 'host_url': 'https://ww... | {'street': 'Honolulu, HI, United States', 'sub... | {'availability_30': 16, 'availability_60': 46,... | {'review_scores_accuracy': 9, 'review_scores_c... | [{'_id': '4765259', 'date': 2013-05-24 04:00:0... | 2013-05-24 04:00:00 | 2019-02-07 05:00:00 | NaN | NaN | |
| 2 | 10021707 | https://www.airbnb.com/rooms/10021707 | Private Room in Bushwick | Here exists a very cozy room for rent in a sha... | Here exists a very cozy room for rent in a sha... | Apartment | Private room | Real Bed | 14 | 1125 | flexible | 2019-03-06 05:00:00 | 2019-03-06 05:00:00 | 1 | 1 | 1.0 | 1 | 1.5 | [Internet, Wifi, Air conditioning, Kitchen, Bu... | 40.00 | NaN | NaN | NaN | 0.00 | 1 | {'thumbnail_url': '', 'medium_url': '', 'pictu... | {'host_id': '11275734', 'host_url': 'https://w... | {'street': 'Brooklyn, NY, United States', 'sub... | {'availability_30': 0, 'availability_60': 0, '... | {'review_scores_accuracy': 10, 'review_scores_... | [{'_id': '61050713', 'date': 2016-01-31 05:00:... | 2016-01-31 05:00:00 | 2016-01-31 05:00:00 | NaN | NaN | |||||||
| 3 | 10030955 | https://www.airbnb.com/rooms/10030955 | Apt Linda Vista Lagoa - Rio | Quarto com vista para a Lagoa Rodrigo de Freit... | Quarto com vista para a Lagoa Rodrigo de Freit... | Apartment | Private room | Real Bed | 1 | 1125 | flexible | 2019-02-11 05:00:00 | 2019-02-11 05:00:00 | 2 | 1 | 1.0 | 0 | 2.0 | [TV, Cable TV, Internet, Wifi, Air conditionin... | 701.00 | NaN | NaN | 250.00 | 0.00 | 1 | {'thumbnail_url': '', 'medium_url': '', 'pictu... | {'host_id': '51496939', 'host_url': 'https://w... | {'street': 'Rio de Janeiro, Rio de Janeiro, Br... | {'availability_30': 28, 'availability_60': 58,... | {} | [] | NaT | NaT | 1000.00 | NaN | |||||||
| 4 | 1003530 | https://www.airbnb.com/rooms/1003530 | New York City - Upper West Side Apt | Murphy bed, optional second bedroom available.... | Murphy bed, optional second bedroom available.... | Great neighborhood - many terrific restaurants... | My cat, Samantha, are in and out during the su... | Conveniently located near 1, 2, 3, B & C subwa... | New York City! | No smoking is permitted in the apartment. All ... | Apartment | Private room | Real Bed | 12 | 360 | strict_14_with_grace_period | 2019-03-07 05:00:00 | 2019-03-07 05:00:00 | 2 | 1 | 1.0 | 70 | 1.0 | [Internet, Wifi, Air conditioning, Kitchen, El... | 135.00 | NaN | NaN | 135.00 | 0.00 | 1 | {'thumbnail_url': '', 'medium_url': '', 'pictu... | {'host_id': '454250', 'host_url': 'https://www... | {'street': 'New York, NY, United States', 'sub... | {'availability_30': 0, 'availability_60': 0, '... | {'review_scores_accuracy': 10, 'review_scores_... | [{'_id': '4351675', 'date': 2013-04-29 04:00:0... | 2013-04-29 04:00:00 | 2018-08-12 04:00:00 | 0.00 | NaN |
📥 Via Web Scrapping
Data is available in different structures and format. These formats are:
- Structured Data Data that can be displayed in tabular formats. Often the format you find via Databases, CSV files, and sometimes APIs.
- Unstructured Data These are data that can't readily be presented as tables. It may include images, audio files, documents.
- Semi-Structured Data These are structured data that can't exactly fit in a tabular formats. For example, data that's represented as nested objects. (See the COVID API Response; the top level represents all the aggregates, then region specific data, county, city, ...etc. Each of those levels don't necessary contain the same data elements, and may include different features or properties. These are data that are often shared as APIs, JSON files, ...etc.
One of the semi-structured-to unstructured data is data that's available on websites. They're not exactly always in a consumable state (even if they're tables). One way we can take advantage of this information is by Web Scrapping.
This is the process of extracting data from websites.
Let's say we found this data on Wikipedia on the world distribution of wealth. The page contains this information in tables with no API or an easily downloadable CSV files.

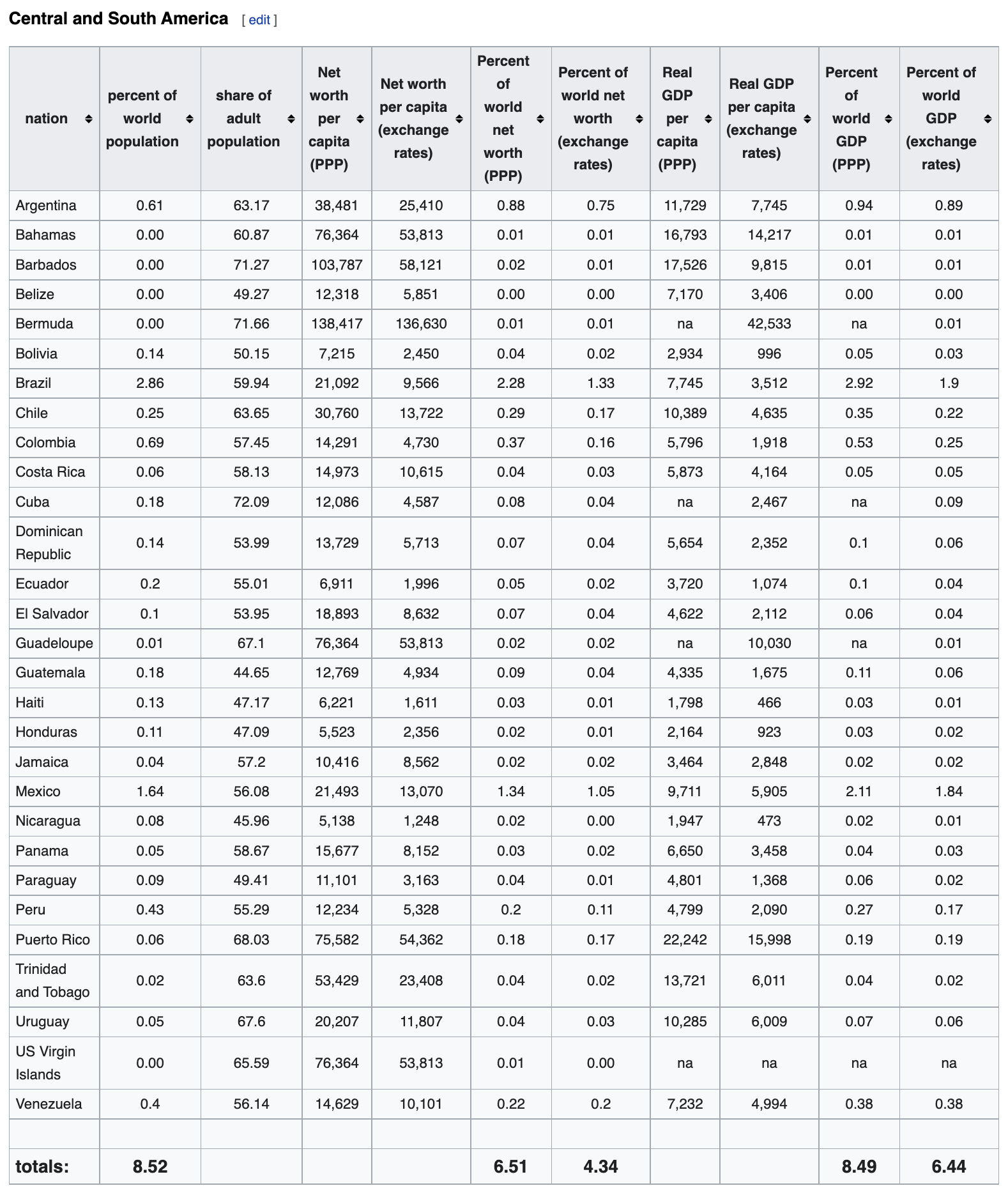
and so on for every continent.
Sidebar: HTML Tables
If you're not familiar with HTML as a markup language. Please review the following website. For this particular part, we're only looking at the Table Markups.
<table>
<thead>
<tr>
<th>Header cell 1</th>
<th>Header cell 2</th>
</tr>
</thead>
<tbody>
<tr>
<td>Row 1 - Cell 1</td>
<td>Row 1 - Cell 2</td>
</tr>
<tr>
<td>Row 2 - Cell 1</td>
<td>Row 2 - Cell 2</td>
</tr>
</tbody>
</table>
If you look at the Wikipedia page, above, you'll see there are multiple sections and html elements on the page. You'll also see multiple tables on the page. The browser receives the data as HTML code, and parses it to present it in a human-friendly format. To see the underlying HTML code, you can open the page inspector/developer tools.
For any chromium-based browser (Chrome, Firefox, Brave, Edge, ...), you should be able to see the same option.
See how you can see the code elements and what they represent on the web page.
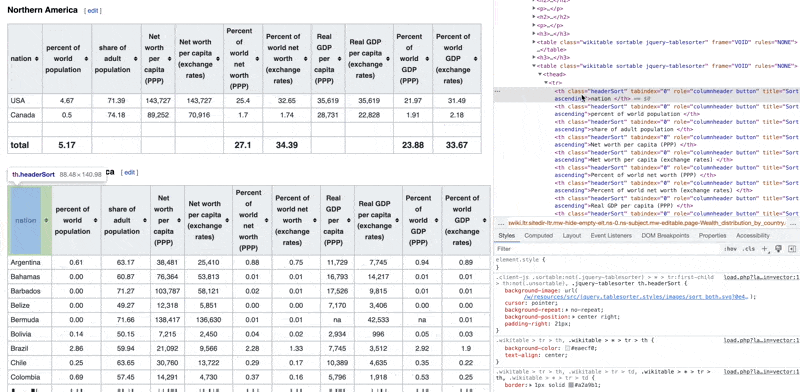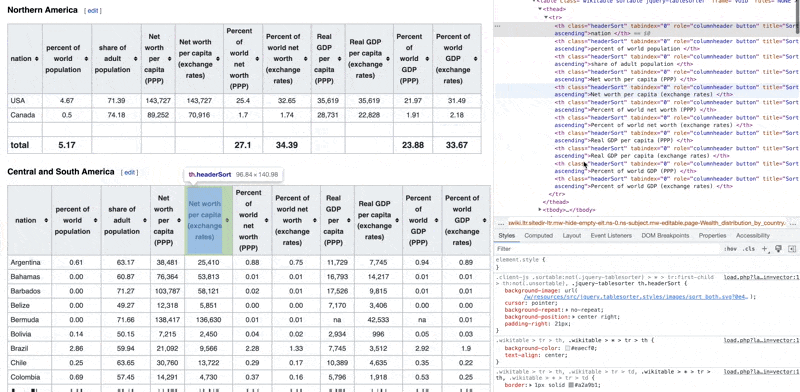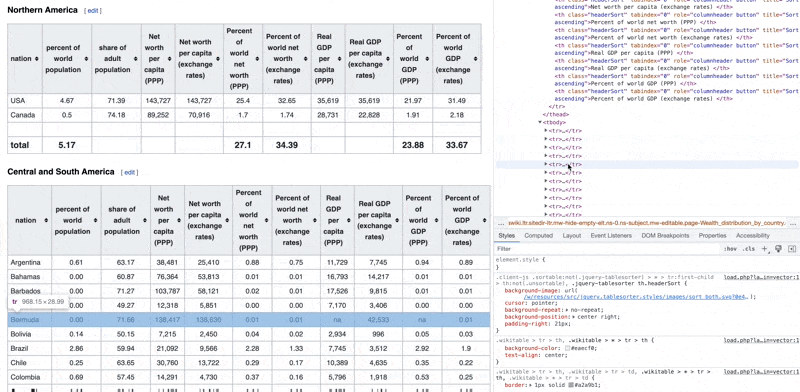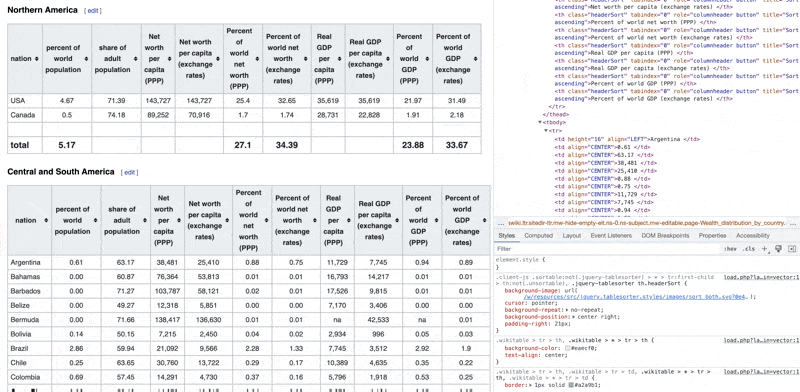
Now we need to see if we can get the HTML code from this page to parse and extract the data from it. So we'll download the content of the URL as a string first.
We'll use the URLLib Package. This Package contains multiple modules. The one we're interested in here is the Request module, which contains multiple functions related to opening and reading URLs.

Please take a moment to review the documentation page, especially the Examples section. You'll need to be familiar with how you can review and understand documentations.
Understanding the documentation is not going to be outdated, The libraries will. These tools will keep on getting updates. Don't memorize the syntax for those libraries but learn how to understand their documentation. That's the skill that you should learn from this lesson.
import urllib.request
html = urllib.request.urlopen("https://en.wikipedia.org/wiki/Wealth_distribution_by_country").read(500) # Read the first 500 characters
html
you can run the previous cell again without passing any numbers in the read function. This will return the entirety of the page. the problem there now is that we have to figure out ways to parse HTML string we receive to find the different elements of the page we're interested in. (not a very easy thing to do)
For a moment, I thought the parse module of the same package would be the answer here, however this module parses the URL itself.
Thankfully, some developer ran into the same problem. They developed and release BeautifulSoup
This is a python package that's built for HTML web scrapping, it's able to parse and interface with HTML documents.
It's a third party package, so I will need to install it first pipenv install beautifulsoup4
Let's now get the wikipedia page using BeautifulSoup:
from bs4 import BeautifulSoup
import requests
url = "https://en.wikipedia.org/wiki/Wealth_distribution_by_country"
page = requests.get(url) # Get the page
soup = BeautifulSoup(page.content, 'html.parser') # Parse the HTML as a string
print(soup.prettify()) # Print the parsed data of html
tables = soup.find_all('table')
# Get the first table
df = pd.read_html(str(tables[0]))[0]
df
| nation | percent of world population | share of adult population | Net worth per capita (PPP) | Net worth per capita (exchange rates) | Percent of world net worth (PPP) | Percent of world net worth (exchange rates) | Real GDP per capita (PPP) | Real GDP per capita (exchange rates) | Percent of world GDP (PPP) | Percent of world GDP (exchange rates) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | USA | 4.67 | 71.39 | 143727.0 | 143727.0 | 25.4 | 32.65 | 35619.0 | 35619.0 | 21.97 | 31.49 |
| 1 | Canada | 0.50 | 74.18 | 89252.0 | 70916.0 | 1.7 | 1.74 | 28731.0 | 22828.0 | 1.91 | 2.18 |
| 2 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | total | 5.17 | NaN | NaN | NaN | 27.1 | 34.39 | NaN | NaN | 23.88 | 33.67 |
We're able to get the table into a pandas DataFrame here. however, we don't really need to the last 2 rows here; the second form last is just a empty separator row, and the other is a total row. let's use pandas functions to get rid of those 2 rows.
# remove the last 2 rows of pandas DataFrame
df = df[:-2]
df
| nation | percent of world population | share of adult population | Net worth per capita (PPP) | Net worth per capita (exchange rates) | Percent of world net worth (PPP) | Percent of world net worth (exchange rates) | Real GDP per capita (PPP) | Real GDP per capita (exchange rates) | Percent of world GDP (PPP) | Percent of world GDP (exchange rates) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | USA | 4.67 | 71.39 | 143727.0 | 143727.0 | 25.4 | 32.65 | 35619.0 | 35619.0 | 21.97 | 31.49 |
| 1 | Canada | 0.50 | 74.18 | 89252.0 | 70916.0 | 1.7 | 1.74 | 28731.0 | 22828.0 | 1.91 | 2.18 |
But that's only the first table on the page. Let's import all of those table dynamically
print('we have %1d tables' % (len(tables)))
for i in range(1, len(tables)):
df = pd.concat([df, pd.read_html(str(tables[i]))[0]], ignore_index=True)
df = df[:-2]
df
| nation | percent of world population | share of adult population | Net worth per capita (PPP) | Net worth per capita (exchange rates) | Percent of world net worth (PPP) | Percent of world net worth (exchange rates) | Real GDP per capita (PPP) | Real GDP per capita (exchange rates) | Percent of world GDP (PPP) | Percent of world GDP (exchange rates) | rank | nation.1 | percent of world population.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | USA | 4.67 | 71.39 | 143727.0 | 143727.0 | 25.40 | 32.65 | 35619.0 | 35619.0 | 21.97 | 31.49 | NaN | NaN | NaN |
| 1 | Canada | 0.50 | 74.18 | 89252.0 | 70916.0 | 1.70 | 1.74 | 28731.0 | 22828.0 | 1.91 | 2.18 | NaN | NaN | NaN |
| 2 | Argentina | 0.61 | 63.17 | 38481.0 | 25410.0 | 0.88 | 0.75 | 11729 | 7745 | 0.94 | 0.89 | NaN | NaN | NaN |
| 3 | Bahamas | 0.00 | 60.87 | 76364.0 | 53813.0 | 0.01 | 0.01 | 16793 | 14217 | 0.01 | 0.01 | NaN | NaN | NaN |
| 4 | Barbados | 0.00 | 71.27 | 103787.0 | 58121.0 | 0.02 | 0.01 | 17526 | 9815 | 0.01 | 0.01 | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 335 | Chad | 0.13 | NaN | 1728.0 | 353 | NaN | NaN | NaN | NaN | NaN | NaN | 167.0 | Sierra Leone | 0.07 |
| 336 | Guinea-Bissau | 0.02 | NaN | 1673.0 | 329 | NaN | NaN | NaN | NaN | NaN | NaN | 168.0 | Chad | 0.13 |
| 337 | Yemen | 0.29 | NaN | 1425.0 | 329 | NaN | NaN | NaN | NaN | NaN | NaN | 169.0 | Niger | 0.19 |
| 338 | Ethiopia | 0.01 | NaN | 1414.0 | na | NaN | NaN | NaN | NaN | NaN | NaN | 170.0 | Burundi | na |
| 339 | Congo, Democratic Republic | 0.82 | NaN | 1402.0 | 298 | NaN | NaN | NaN | NaN | NaN | NaN | 171.0 | Tajikistan | 0.1 |
340 rows × 14 columns