Regression
What is Regression?
Linear Regression and Polynomial Regression are supervised regression algorithms. Regression models are used to we predict numerical values instead of categories or classes.
Regression models finds relationships between:
- one or more independent variables, or explanatory variables,
- and a target variable or dependent variable.
Types of Regression
- Linear Regression
- Simple Linear Regression (2D)
- Multiple Linear Regression (3D or more)
- Polynomial Regression
- Simple Polynomial Regression (2D)
- Multiple Polynomial Regression (3D or more)
The Goal of Regression
given the following dataset. if we want to determine the income of a person based on their education and seniority. We can use a regression model that learns from historical data to create a model that describes the relationship between the education and seniority of a person and their income. and use that model to make estimations.
# import csv file
import pandas as pd
income_df = pd.read_csv('data/income2.csv')
income_df.head(6)
| Education | Seniority | Income | |
|---|---|---|---|
| 0 | 21.586207 | 113.103448 | 99.917173 |
| 1 | 18.275862 | 119.310345 | 92.579135 |
| 2 | 12.068966 | 100.689655 | 34.678727 |
| 3 | 17.034483 | 187.586207 | 78.702806 |
| 4 | 19.931034 | 20.000000 | 68.009922 |
| 5 | 18.275862 | 26.206897 | 71.504485 |
a quick EDA, can show a strong positive correlation between years of education and income (0.9), and a less-strong positive correlation between seniority level and income (0.52).
# Visualize the correlation matrix
import seaborn as sns
import matplotlib.pyplot as plt
income_corr = income_df.corr()
sns.heatmap(income_corr, annot=True, cmap='coolwarm')
plt.show()
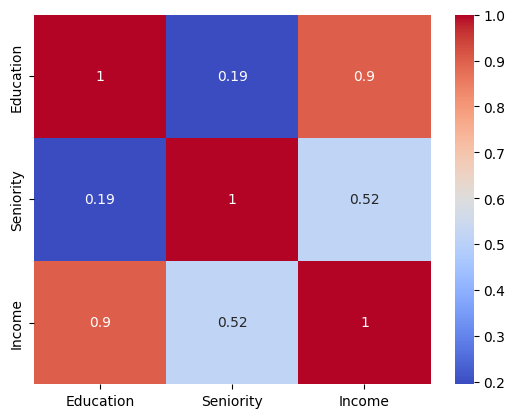
Correlation however doesn't tell us what type of relationship it is, and if it's linear or not. Also, while the correlation between seniority and income may be less strong, it can be strong when used in combination with years of education. One of the tasks Feature Engineering help us with.
# Visualize a scatter plot between income and education
sns.scatterplot(x='Education', y='Income', data=income_df)
plt.show()
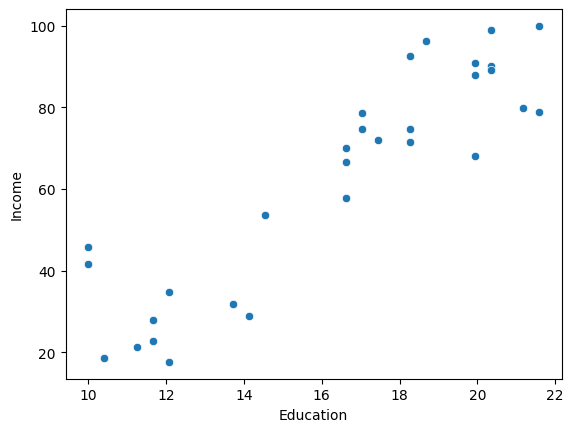
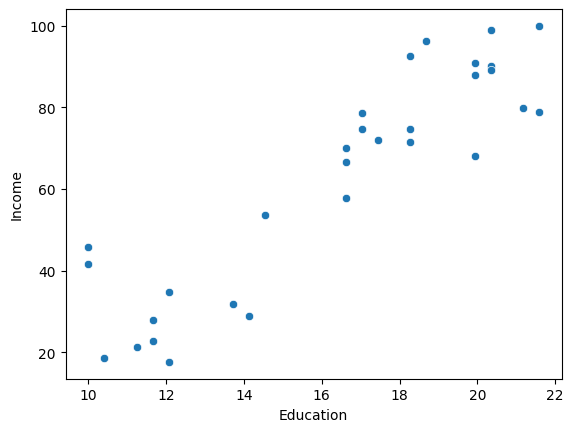
Visualizing the data using a scatter plot, shows us that there is a linear relationship between years of education and income.
Let's include, seniority level in the mix.
# visualize a 3d scatter plot between Education, Seniority, and Income using mpl_toolkits
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(5,5))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(income_df['Education'], income_df['Seniority'], income_df['Income'])
ax.set_xlabel('Education')
ax.set_ylabel('Seniority')
ax.set_zlabel('Income')
plt.show()
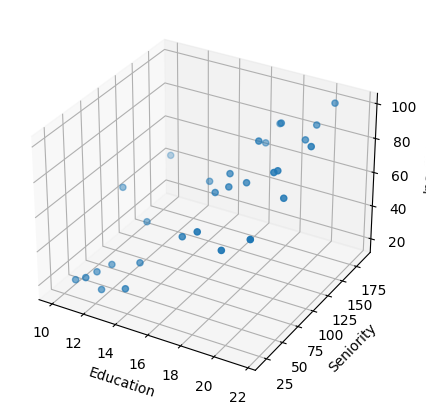
a static 3d scatter plot is kind of hard to read, let's create an interactive one using plotly.
# visualize a 3d scatter plot between Education, Seniority, and Income using plotly
import plotly.express as px
fig = px.scatter_3d(income_df, x='Education', y='Seniority', z='Income')
fig.update_layout(margin=dict(l=0, r=0, b=0, t=0))
fig.show()
I couldn't find a way to make the plot interactive in the course note, so here's a gif
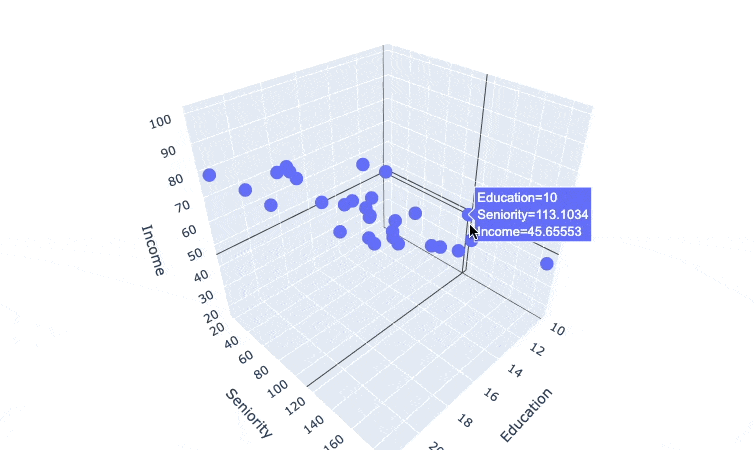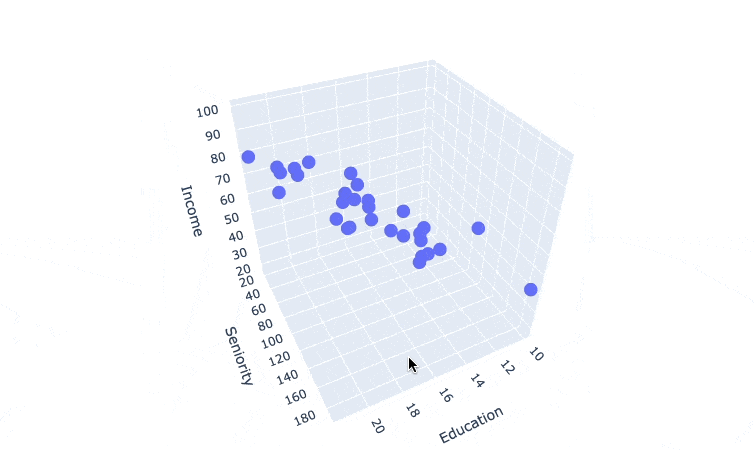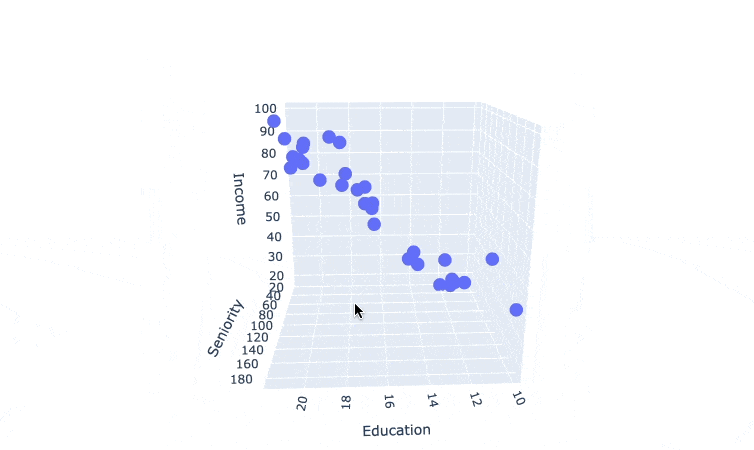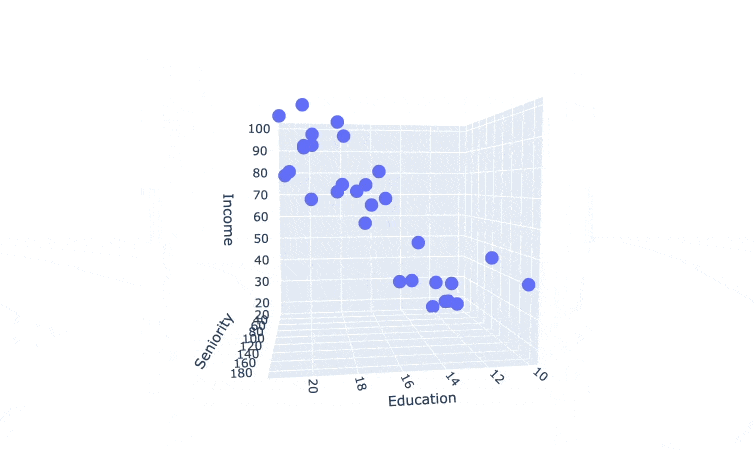
we can see a surface model that can cut through the data points. which suggest that we can build a multiple linear regression model here.
The goal of Regression Models is to find that line (for simple linear regression) or surface (for multiple linear regression) that best fits the data.
Model and Notations
Whenever you learn about a new machine learning algorithm, you should learn about the model and the notations used to describe it.
Generally, the data notations are described as follows:
- Every dataset we work with has a number (m) of (records, observations, signals, instances, data point), these are all synonyms.
- Each of those observations ia a vector of (features, independent variables, explanatory variables, predictors, dimensions, attributes) (x) and a for labelled data, or data we use in supervised learning we also have a target (y). These are also called targets, dependent variables, or a responses, classes, or a categories.
- the number of features is (n).
so for this dataset, we can say that:
- we have 30 records, m = 30
- we have 2 features, n = 2
- features are years of education, and seniority level
- target is income
The simple linear regression model is the same as the line equation:
where:
- m: slope
- c: y-intercept or the bias term, or the value of y when x = 0
but since we have different notation for what (m) is, we represent the simple linear regression model as:
where:
- : the predicted value, also called the hypothesis function
- : the bias term, or the y-intercept
- : the slope of the line
Let's plot a few lines to remember the equation.
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-5, 5, 11)
# a funciton that takes a string equation describing a line and color parameter and plots the line
def plot_line(y, color):
y_ = eval(y)
plt.plot(x, y_, label=f'y={y}', marker='o', markersize=5, color=color)
plt.legend(loc='best')
plt.xlabel('x')
plt.ylabel('y')
# Calling the plot line function with different parameters
plot_line(y='x', color='red')
plot_line(y='3*x+5', color='blue')
plot_line(y='-2*x+4', color='green')
plot_line(y='2*x', color='purple')
plt.grid()
plt.show()
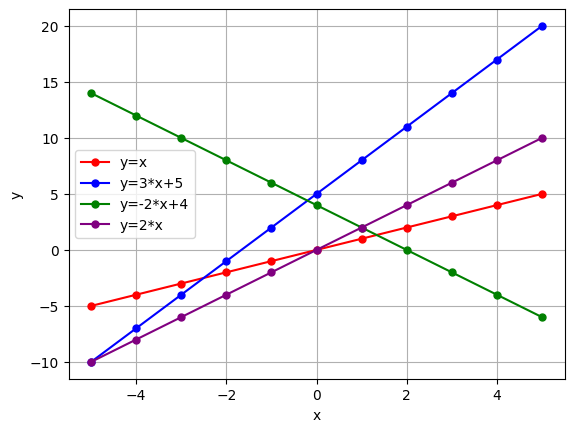
Simple Linear Regression Model:
where:
- : the predicted value, also called the hypothesis function
- : the bias term, or the y-intercept
- : the slope of the line
it's as if the was multiplied by
if we had an extra feature/dimension (n=2), the equation would be generalized to represent a plane or a surface as:
fig = plt.figure()
ax = fig.add_subplot(111,projection='3d')
x1, x2 = np.meshgrid(range(10), range(10))
y_hat = (9 - x1 - x2)
ax.plot_surface(x1, x2, y_hat, alpha=0.5)
plt.show()
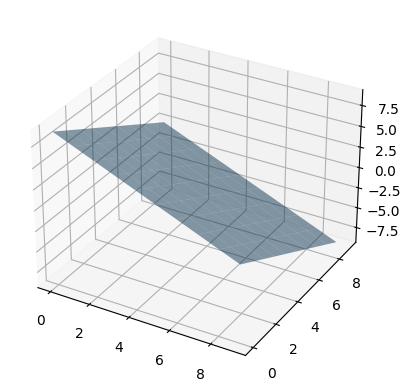
if we had n features/dimensions, the equation would be generalized to represent a hyperplane or a hypersurface as:
or the vectorized form of this would be:
where:
- : the matrix of features, or the matrix of independent variables
- : the vector of parameters, or the vector of coefficients, the values we're adjusting to fit the model.
- : the predicted value, also called the hypothesis function
Vectorized forms are a way to represent the same equation in a more compact way. Many mathematical libraries are more optimized to work with vectorized forms.
so how do we get the best values for ? how do we call one model better than another? how do we know if our model is good or not?
We use Performance Measures/Cost Functions/Lost Functions to evaluate our model.
Cost Function
In simple linear regression, we aim to get a a line that can represent the data we have as best as possible.
If you had the following lines, which one would you choose? and why?
# a pandas dataframe with 2 columns: x and y
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
x = [1, 1.5, 2.5, 3, 4]
y = [1, 2.3, 2.1, 3, 2.9]
df = pd.DataFrame({'x': x, 'y': y})
# plot the data
# Scatter plot of the dots
f, ax = plt.subplots(figsize=(5,5))
ax.scatter(df['x'], df['y'], s=60)
# Plot an arbitrary line
x = np.linspace(0, 4, 11)
y_bad = 2.2+ -x
y_good = x + 0.5
y_better = 0.55789474*x + 0.92105263
ax.plot(x,y_bad, label=f'bad: y=2.2 - x', color='red')
ax.plot(x,y_good, label=f'good: y=0.5 + x', color='orange')
ax.plot(x,y_better, label=f'better: y= 0.92 + 0.558 x', color='green')
ax.legend(loc='best')
ax.grid(alpha=0.2)
plt.show()
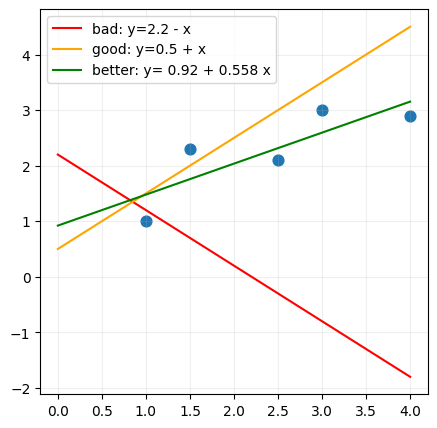
- We can't choose a line based on how it looks, we need to use a performance measure to evaluate the model.
- We can't use arbitrary points to draw a line using the slope:
One of the common performance measures is mean of the squared errors or the squared residuals .
How? we take the difference between the actual value and the predicted value, and we square it. and we do that for every data point, and we get the mean of all those values.
We want to find the that gets us the lowers .
Here's an explanation of calculating the for a simple linear regression model. (we won't be doing this manually)
import pandas as pd
df = pd.DataFrame([[1, 1], [1.5, 2.3], [2.5, 2.1], [3, 3], [4, 2.9]], columns=['x', 'y'])
df
| x | y | |
|---|---|---|
| 0 | 1.0 | 1.0 |
| 1 | 1.5 | 2.3 |
| 2 | 2.5 | 2.1 |
| 3 | 3.0 | 3.0 |
| 4 | 4.0 | 2.9 |
we'll just start with a random line, any line,
# plot the data
import matplotlib.pyplot as plt
# Scatter plot of the dots
f, ax = plt.subplots(figsize=(5,5))
ax.scatter(df['x'], df['y'])
# Plot an arbitrary line
x = np.linspace(0, 4, 11)
y = 0*x + 2.2
ax.plot(x,y, label=f'y=2.25')
ax.grid(alpha=0.2)
plt.show()
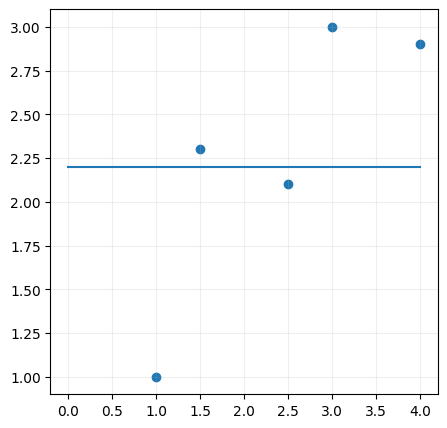
and then calculate the distance between the line and the data points.
# plot the data
import matplotlib.pyplot as plt
# Scatter plot of the dots
f, ax = plt.subplots(figsize=(5,5))
ax.scatter(df['x'], df['y'])
# Plot an arbitrary line
x = np.linspace(0, 4, 11)
y = 0*x + 2.2
ax.plot(x,y, label=f'y=2.25')
# Residuals
ax.plot([1,1],[1, 2.2], color='red', linestyle='dotted', alpha=0.5)
ax.text(1.1, 1.5, '1.2')
ax.plot([1.5,1.5],[2.3, 2.2], color='red', linestyle='dotted', alpha=0.5)
ax.text(1.6, 2.25, '-0.1')
ax.plot([2.5,2.5],[2.1, 2.2], color='red', linestyle='dotted', alpha=0.5)
ax.text(2.6, 2.12, '0.1')
ax.plot([3,3],[3, 2.2], color='red', linestyle='dotted', alpha=0.5)
ax.text(3.1, 2.4, '-0.8')
ax.plot([4,4],[2.9, 2.2], color='red', linestyle='dotted', alpha=0.5)
ax.text(4.1, 2.6, '-0.7')
ax.grid(alpha=0.2)
plt.show()
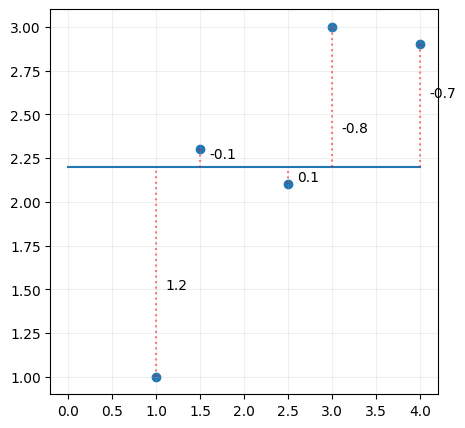
Some of the values are negative, summing the errors may lead to them cancelling each other out, so we square the distance, and we sum all the squared distances,
# plot the data
import matplotlib.pyplot as plt
f, ax = plt.subplots(figsize=(5,5))
ax.scatter(df['x'], df['y'])
x = np.linspace(0, 4, 5)
y = 0*x + 2.2
y_ = 0*df['x'] + 2.2
residuals = (y_ - df['y'])**2
SE = np.sum(residuals)
MSE = np.mean(residuals)
ax.plot(x,y, label=f'y=2.25')
ax.plot([1,1],[1, 2.2], color='red', linestyle='dotted', alpha=0.5)
ax.text(1.1, 1.5, '1.44')
ax.plot([1.5,1.5],[2.3, 2.2], color='red', linestyle='dotted', alpha=0.5)
ax.text(1.6, 2.25, '0.01')
ax.plot([2.5,2.5],[2.1, 2.2], color='red', linestyle='dotted', alpha=0.5)
ax.text(2.6, 2.12, '0.01')
ax.plot([3,3],[3, 2.2], color='red', linestyle='dotted', alpha=0.5)
ax.text(3.1, 2.4, '0.64')
ax.plot([4,4],[2.9, 2.2], color='red', linestyle='dotted', alpha=0.5)
ax.text(4.1, 2.6, '0.49')
ax.text(2, 1.5, f'∑={SE}\nMSE={MSE}', fontsize=20, color='red')
ax.grid(alpha=0.2)
plt.show()
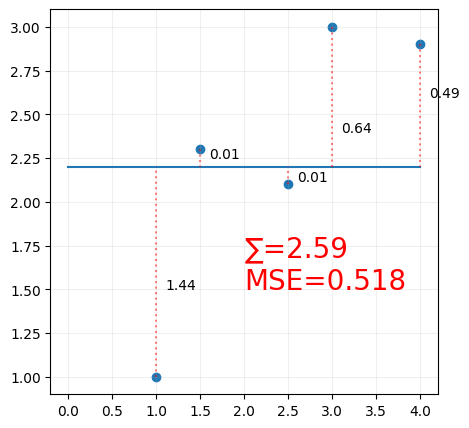
We call this the loss function, or the cost function. and we want to minimize this function.
Rinse and Repeat until we get the best line.
# plot the data
import matplotlib.pyplot as plt
f, ax = plt.subplots(figsize=(5,5))
ax.scatter(df['x'], df['y'])
x = np.linspace(0, 4, 5)
y = x + 0.5
y_ = df['x'] + 0.5
residuals = (y_ - df['y'])**2
SE = np.sum(residuals)
MSE = np.mean(residuals)
ax.plot(x,y, label=f'y=0.5 + x')
ax.plot([1,1],[1, 1.5], color='red', linestyle='dotted', alpha=0.5)
ax.text(1.1, 1.5, '0.25')
ax.plot([1.5,1.5],[2.3, 2], color='red', linestyle='dotted', alpha=0.5)
ax.text(1.6, 2.25, '0.09')
ax.plot([2.5,2.5],[2.1, 3], color='red', linestyle='dotted', alpha=0.5)
ax.text(2.6, 2.12, '0.81')
ax.plot([3,3],[3, 3.5], color='red', linestyle='dotted', alpha=0.5)
ax.text(3.1, 2.4, '0.25')
ax.plot([4,4],[2.9, 4.5], color='red', linestyle='dotted', alpha=0.5)
ax.text(4.1, 2.6, '2.56')
ax.text(1.5, .5, f'∑={SE}\nMSE={MSE}', fontsize=20, color='red')
ax.grid(alpha=0.2)
plt.show()
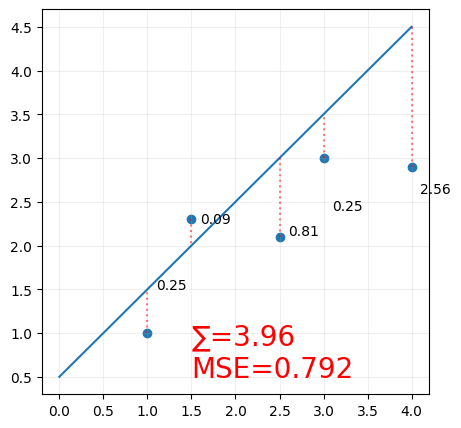
and again
# plot the data
import matplotlib.pyplot as plt
f, ax = plt.subplots(figsize=(5,5))
ax.scatter(df['x'], df['y'])
x = np.linspace(0, 4, 5)
y = 0.5*x + 1
y_ = 0.5*df['x'] + 1
residuals = (y_ - df['y'])**2
SE = np.sum(residuals)
MSE = np.mean(residuals)
ax.plot(x,y, label=f'y= 0.5x + 1')
ax.plot([1,1],[1, 1.5], color='red', linestyle='dotted', alpha=0.5)
ax.text(1.1, 1.5, '0.25')
ax.plot([1.5,1.5],[2.3, 1.75], color='red', linestyle='dotted', alpha=0.5)
ax.text(1.6, 2.25, '0.025')
ax.plot([2.5,2.5],[2.1, 2.25], color='red', linestyle='dotted', alpha=0.5)
ax.text(2.6, 2.12, '0.09')
ax.plot([3,3],[3, 2.5], color='red', linestyle='dotted', alpha=0.5)
ax.text(3.1, 2.4, '0.09')
ax.plot([4,4],[2.9, 3], color='red', linestyle='dotted', alpha=0.5)
ax.text(4.1, 2.6, '0.16')
ax.text(1.5, 1, f'∑={SE}\nMSE={MSE}', fontsize=20, color='red')
ax.grid(alpha=0.2)
plt.show()
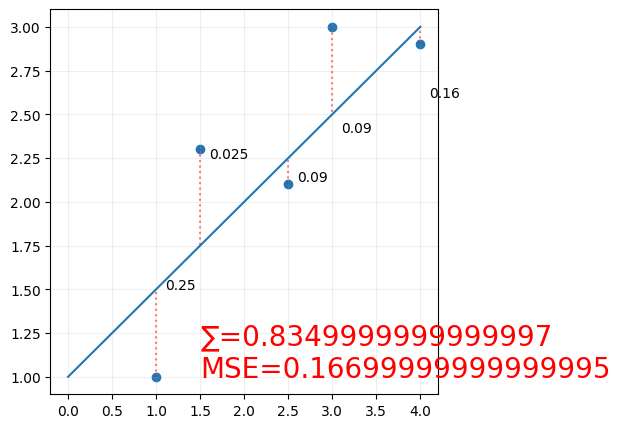
For simple linear regression, since we're only changing 2 parameters ( the slope and the y-intercept), we can plot the cost function as a 3d surface, and we can see that the cost function is a convex function, which means that it has a single global minimum, and we can use gradient descent to find it.
the plot would like a bowl shape, and the minimum value (the optimum values for and is the bottom of the bowl.
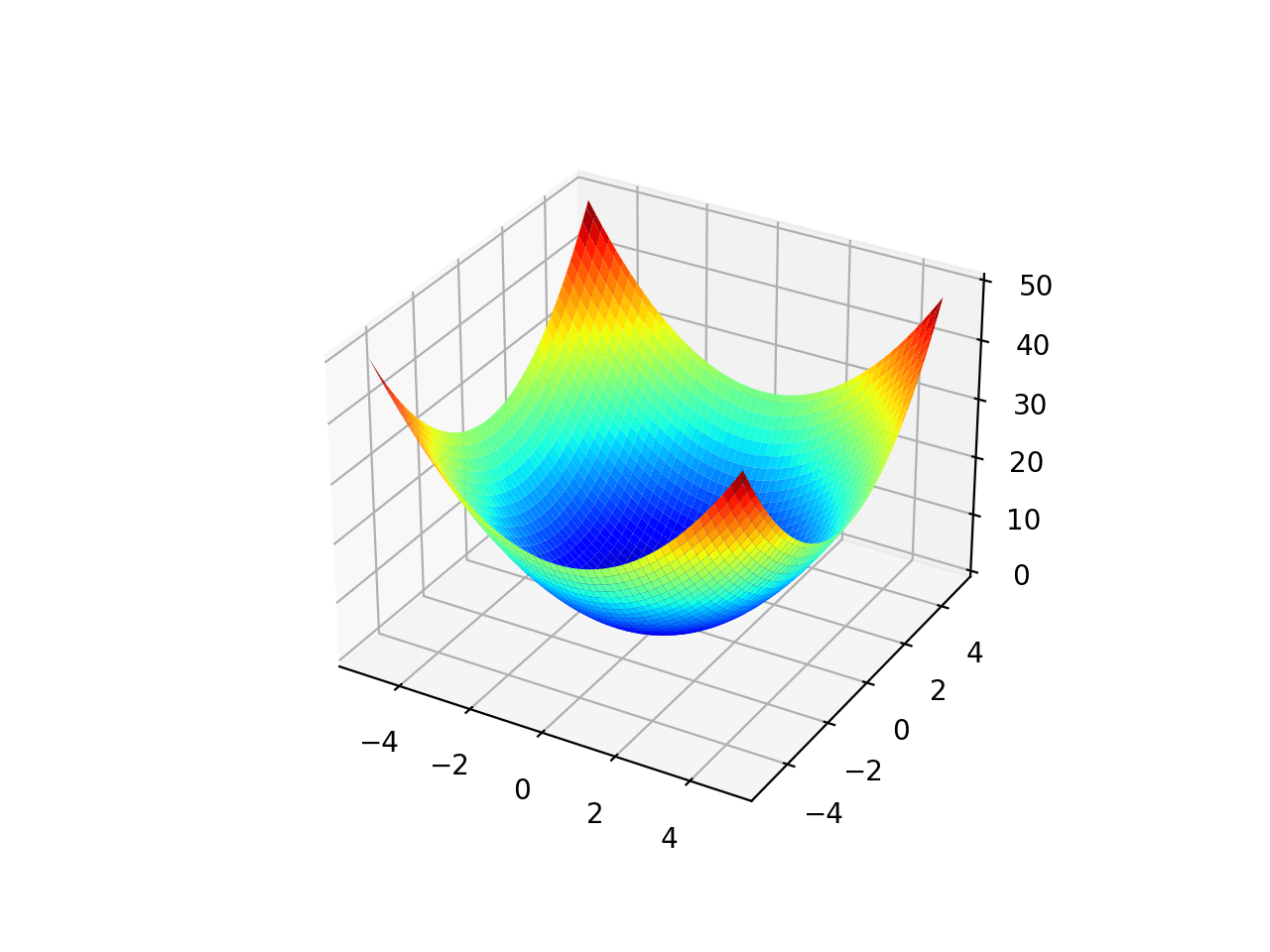
so what is gradient descent? and how does it work?
Gradient Descent
gradient descent is used in many machine learning algorithms, not just linear regression. It's an optimization algorithm that helps us find the minimum of a function.
supposed you're on a mountain, it's dark, it's foggy, and you can only feel the slope of the ground below your feet. A good strategy to get down, is that you feel the ground and move it in the direction of the steepest slope. That is exactly what the gradient descent does.
where:
- theta: the feature coefficients
- eta: the learning rate
everytime you update the coefficients , we get a new , calculate the cost function, and calculate the gradient, and you move in the direction of the gradient, and you keep doing this until you reach the minimum. a point where the gradient is zero (or very close to zero). a value where the update theta values doesn't change.
Using Scikit-Learn
Simple Linear Regression
Scikit-learn abstracts all of the mathematical complexity away from us, and gives us a very simple API to work with.
This may not always be possible for all algorithms, or even desirable, which is why you need to understand the model you're using, to know it's limitations.
# linear regression
from sklearn.linear_model import LinearRegression
import pandas as pd
df = pd.DataFrame({'x': [1, 1.5, 2.5, 3, 4], 'y': [1, 2.3, 2.1, 3, 2.9]})
display(df)
# create a linear regression model
model = LinearRegression()
model.fit(df[['x']], df['y'])
model.coef_, model.intercept_
That's is the model is trained, we can use it to make predictions.
Let's visualize the predictions.
df
| x | y | |
|---|---|---|
| 0 | 1.0 | 1.0 |
| 1 | 1.5 | 2.3 |
| 2 | 2.5 | 2.1 |
| 3 | 3.0 | 3.0 |
| 4 | 4.0 | 2.9 |
import matplotlib.pyplot as plt
# plot the data points
f, ax = plt.subplots(figsize=(5,5))
ax.scatter(df['x'], df['y'])
# plot the regression line
x = np.linspace(0, 4, 5)
y = model.predict(x.reshape(-1,1))
ax.plot(x,y, label=f'y= {model.intercept_} + {model.coef_[0]}x')
# calculate the predictions and residuals
y_hat = model.predict(df[['x']]) # y_hat = model.coef_[0]*df['x'] + model.intercept_
residuals = (y_hat - df['y'])**2
SE = np.sum(residuals)
MSE = np.mean(residuals)
# update the dataframe with an additional column for the predictions
df['y_hat'] = y_hat
display(df)
# loop over the data points in the df
for i, row in df.iterrows():
ax.plot([row['x'], row['x']], [row['y'], row['y_hat']], color='red', linestyle='dotted', alpha=0.5)
y_midpoint = (row['y'] + row['y_hat'])/2
ax.text(row['x']+0.1, y_midpoint, f'{residuals[i]:.5f}')
ax.text(0, 2.5, f'∑={SE:.5f}\nMSE={MSE:.5f}', fontsize=20, color='red')
ax.grid(alpha=0.2)
plt.show()
sns.scatterplot(x='Education', y='Income', data=income_df)
plt.show()
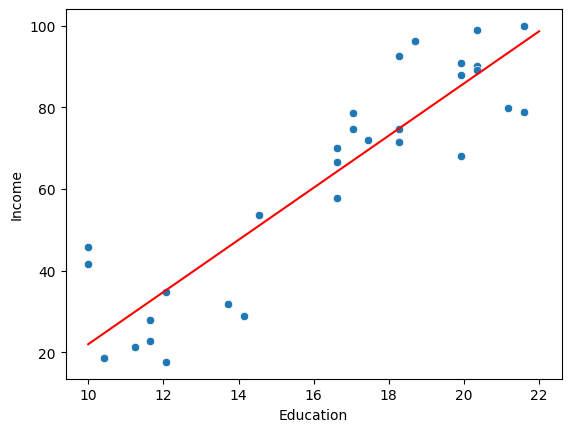
from sklearn.linear_model import LinearRegression
# create and train the model
income_model = LinearRegression()
income_model.fit(income_df[['Education']], income_df['Income'])
# plot the data points
sns.scatterplot(x='Education', y='Income', data=income_df)
# plot the regression line
x = np.linspace(10, 22, 5)
y = income_model.coef_[0]*x + income_model.intercept_
plt.plot(x,y, label=f'y= {income_model.intercept_} + {income_model.coef_[0]}x', color='red')
plt.show()
Multiple Linear Regression
ok let's try multiple linear regression, more than one feature.
from sklearn.linear_model import LinearRegression
income_model = LinearRegression()
income_model.fit(income_df[['Education', 'Seniority']], income_df['Income'])
income_model.coef_, income_model.intercept_
note how the coefficients have multiple values.
## Prepare the data for Visualization
import numpy as np
x_surf, y_surf = np.meshgrid(
np.linspace(income_df.Education.min(), income_df.Education.max(), 100),
np.linspace(income_df.Seniority.min(), income_df.Seniority.max(), 100)
)
surfaceX = pd.DataFrame({'Education': x_surf.ravel(), 'Seniority': y_surf.ravel()})
predictedIncomeForSurface=income_model.predict(surfaceX)
## convert the predicted result in an array
predictedIncomeForSurface=np.array(predictedIncomeForSurface)
predictedIncomeForSurface
# Visualize the Data for Multiple Linear Regression
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(20,10))
### Set figure size
ax = fig.add_subplot(111, projection='3d')
ax.scatter(income_df['Education'],income_df['Seniority'],income_df['Income'],c='red', marker='o', alpha=0.5)
ax.plot_surface(x_surf, y_surf, predictedIncomeForSurface.reshape(x_surf.shape), color='b', alpha=0.3)
ax.set_xlabel('Education')
ax.set_ylabel('Seniority')
ax.set_zlabel('Income')
plt.show()
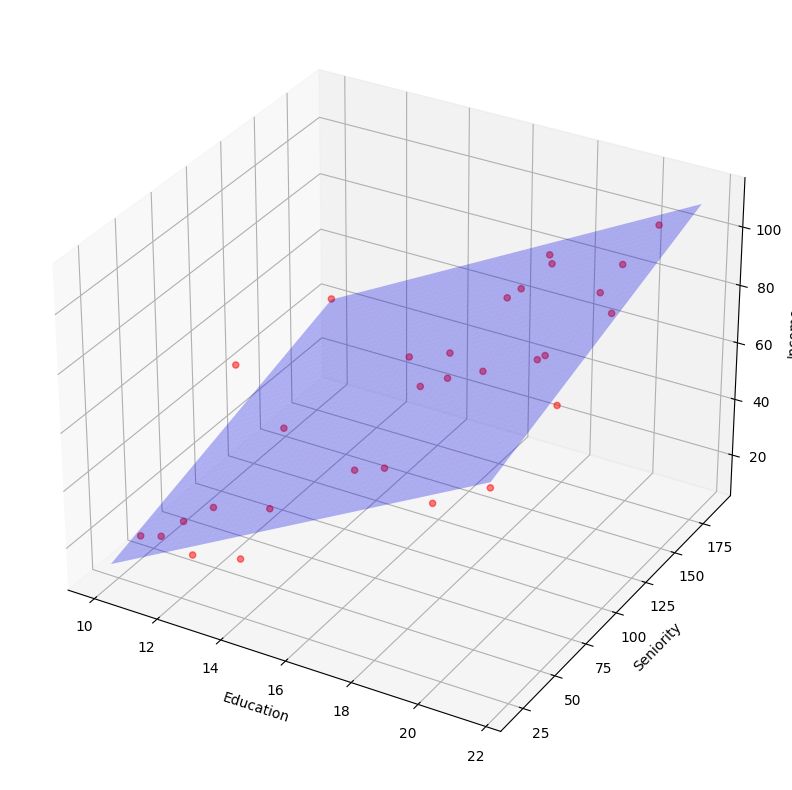
and it doesn't matter how many additional features you add to the model, this would still hold. As long as the model we're predicting can fit this model. Once we're past the 3d, we don't really know if the linear model is approproate for the data, since we can't visualize it.
so as a machine learning professional, you'd be trying different models and algorithms, evaluating them, and then choosing the best one.
We will take next week about how we can evaluate our model, when we can't visualize it.
Polynomial Regression
polynomial regression is a special case of multiple linear regression, where we're using polynomial features instead of linear features.
For a single feature , we can create polynomial features up to degree as:
Let's visualize that.
As the model polynomial degree increases, the model complexity increases, and the model becomes more flexible. and that's why we can fit more complex data with polynomial regression.
:::warn you want to be careful, because if you use a polynomial model with a high degree, you can overfit the data. :::
x = np.linspace(-10, 10, 20)
first_degreee_y = 20*x + 1
second_degree_y = 10*x**2 + 2*x + 1
third_degree_y = 0.5*x**3 + x**2 + 2*x + 1
fourth_degree_y = 0.1*x**4 + 0.5*x**3 + x**2 + 2*x + 1
# visualize the data with different polynomial degrees
f, ax = plt.subplots(figsize=(5,5))
ax.plot(x,first_degreee_y, label='1st degree')
ax.plot(x,second_degree_y, label='2nd degree')
ax.plot(x,third_degree_y, label='3rd degree')
ax.plot(x,fourth_degree_y, label='4th degree')
ax.legend()
ax.grid(alpha=0.2)
plt.show()
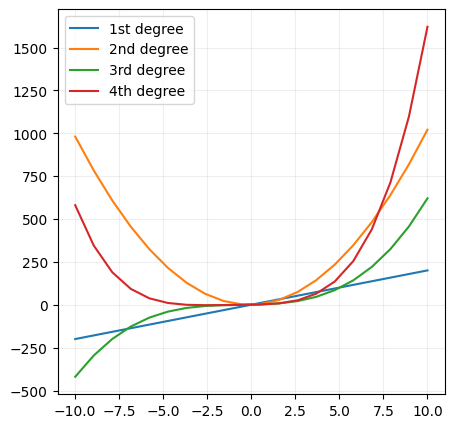
Now mathematically, polynomial regression is the same as multiple linear regression, except that we're using polynomial features instead of linear features.
this was linear regression:
this is polynomial regression of the third degree for a single feature: \;\theta_{0} + $$\;\theta{1{x1}}x{1} + \theta{2{x1}}x{1}^{2} + \theta{3{x1}}x{1}^{3} +\;\theta{1{x2}}x{2} + \theta{2{x2}}x{2}^{2} + \theta{3{x2}}x{2}^{3} + ... $$
For every feature x, you get multiple terms with different degrees. and you can see that the model is getting more complex as the degree increases.
income2_df = pd.read_csv('data/position_salaries.csv')
sns.scatterplot(x='Level', y='Salary', data=income2_df)
plt.show()
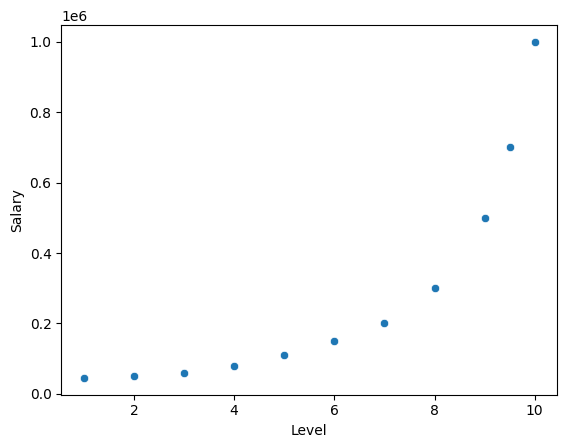
If I was to fit it using linear regression, I would get a straight line, and if I was to fit it using polynomial regression, I would get a curved line.
income2_model = LinearRegression()
income2_model.fit(income2_df[['Level']], income2_df['Salary'])
LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression()
sns.scatterplot(x='Level', y='Salary', data=income2_df)
x2 = np.linspace(1, 12, 20)
y2 = income2_model.predict(x2.reshape(-1,1))
y_hat = model.predict(income2_df[['Level']])
residuals = (y_hat - income2_df['Salary'])**2
MSE = np.mean(residuals)
plt.text(1, 800000, f'MSE={MSE:.5f}', fontsize=15, color='red')
plt.plot(x2,y2, label=f'y= {income2_model.intercept_} + {income2_model.coef_[0]}x', color='red')
plt.show()
/Users/gilanyym/.local/share/virtualenvs/IT4063C.github.io-cdKt1PoY/lib/python3.10/site-packages/sklearn/base.py:450: UserWarning:
X does not have valid feature names, but LinearRegression was fitted with feature names
/Users/gilanyym/.local/share/virtualenvs/IT4063C.github.io-cdKt1PoY/lib/python3.10/site-packages/sklearn/base.py:493: FutureWarning:
The feature names should match those that were passed during fit. Starting version 1.2, an error will be raised.
Feature names unseen at fit time:
- Level
Feature names seen at fit time, yet now missing:
- x
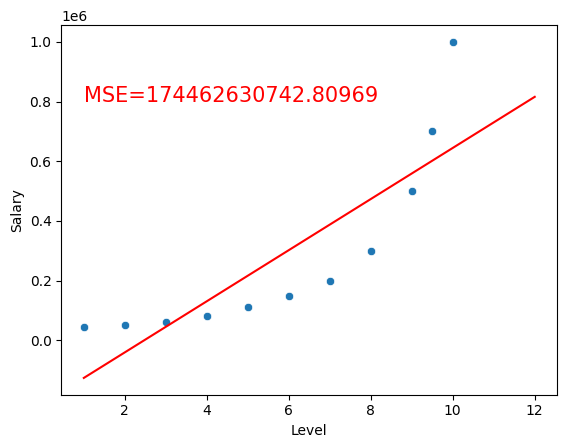
But if we use Polynomial Features, we transform the data to a higher dimension, and we can fit a linear model to it.
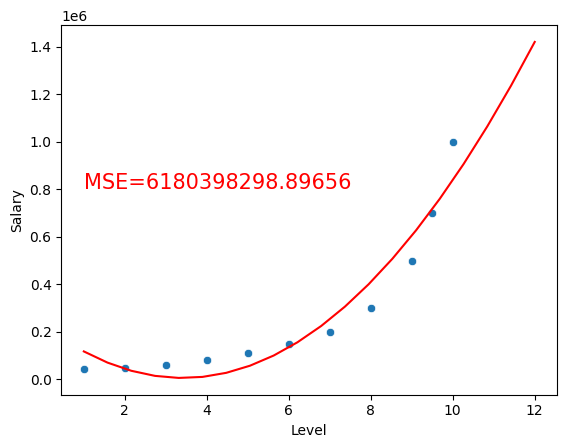
For example using a second degree polynomial:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
poly_X= poly.fit_transform(income2_df[['Level']])
polynomial_income2_model = LinearRegression()
polynomial_income2_model.fit(poly_X, income2_df['Salary'])
sns.scatterplot(x='Level', y='Salary', data=income2_df)
x3 = np.linspace(1, 12, 20)
y3 = polynomial_income2_model.predict(poly.fit_transform(x3.reshape(-1,1)))
y_hat = polynomial_income2_model.predict(poly.fit_transform(income2_df[['Level']]))
residuals = (y_hat - income2_df['Salary'])**2
MSE = np.mean(residuals)
plt.text(1, 800000, f'MSE={MSE:.5f}', fontsize=15, color='red')
plt.plot(x3,y3, color='red')
plt.show()
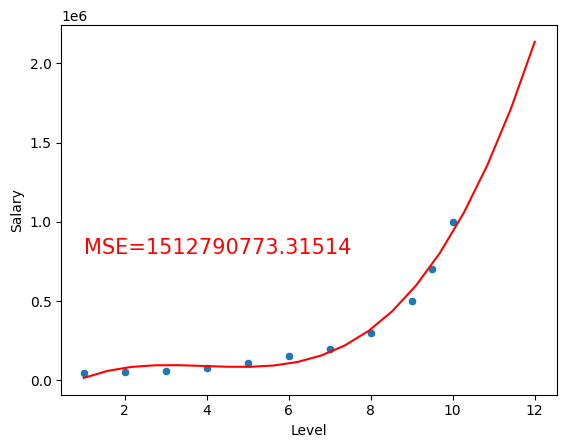
using a third degree polynomial:
from sklearn.preprocessing import PolynomialFeatures
poly3 = PolynomialFeatures(degree=3)
poly3_X= poly3.fit_transform(income2_df[['Level']])
polynomial3_income2_model = LinearRegression()
polynomial3_income2_model.fit(poly3_X, income2_df['Salary'])
sns.scatterplot(x='Level', y='Salary', data=income2_df)
x4 = np.linspace(1, 12, 20)
y4 = polynomial3_income2_model.predict(poly3.fit_transform(x4.reshape(-1,1)))
y_hat = polynomial3_income2_model.predict(poly3.fit_transform(income2_df[['Level']]))
residuals = (y_hat - income2_df['Salary'])**2
MSE = np.mean(residuals)
plt.text(1, 800000, f'MSE={MSE:.5f}', fontsize=15, color='red')
plt.plot(x4,y4, color='red')
plt.show()
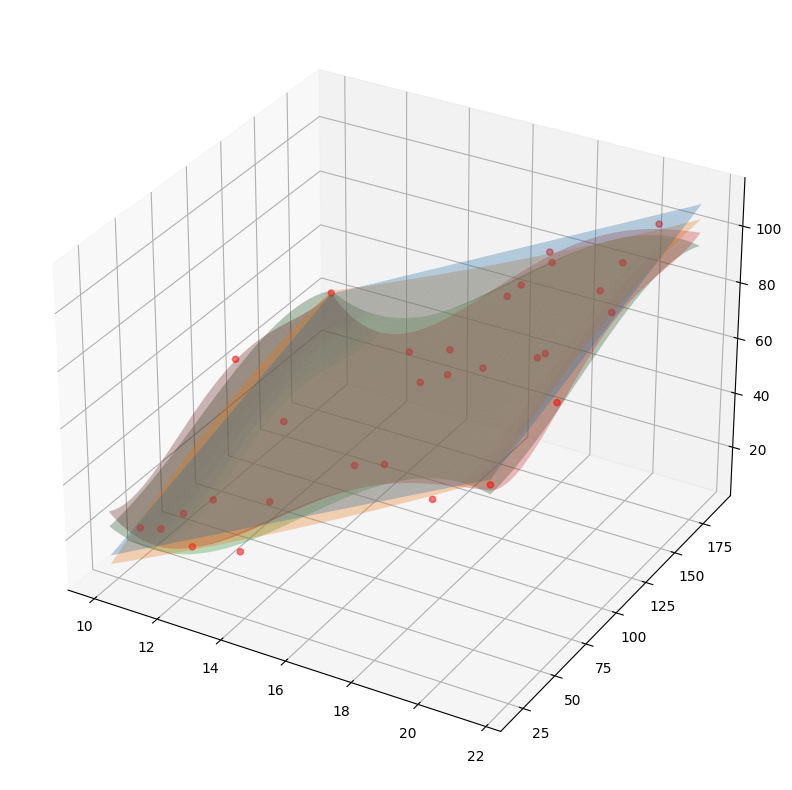
Multiple Polynomial Regression
Here I'm using the pipeline to transform the data, and then fit the model.
# Visualize the same data using different polynomial degrees
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
fig = plt.figure(figsize=(20,10))
### Set figure size
ax = fig.add_subplot(111, projection='3d')
ax.scatter(income_df['Education'],income_df['Seniority'],income_df['Income'],c='red', marker='o', alpha=0.5)
for degree in [1,2,3,4]:
model = make_pipeline(PolynomialFeatures(degree), LinearRegression())
model.fit(income_df[['Education', 'Seniority']], income_df['Income'])
predictedIncomeForSurface=model.predict(surfaceX)
ax.plot_surface(x_surf, y_surf, predictedIncomeForSurface.reshape(x_surf.shape), alpha=0.3)