Exploratory Data Analysis (EDA)
What is EDA?
Classical Statistical analysis was almost always focusing on what's known inferential statistics by deriving estimates about a population or by by hypotheses testing or confirmatory data analysis.
Confirmatory Data analysis is For example, when you want to know if a new drug is effective in treating a disease. Your hypothesis could be that the drug is effective, and you want to use data to prove that. so you design an experiment where you give the drug to a group of patients and you give a placebo to another group of patients. You then measure the outcome of the disease in both groups and compare the results. If the results show that that to a certain degree of confidence (p-value) the drug is effective, you can conclude that your hypothesis was correct. This is an example of confirmatory data analysis.
estimating parameters about a population is for example when you're looking to see how many of the university community like a certain service at the university. You can't ask everyone. I mean it's difficult enough to get students to submit assignments on time. So you take a sample of students and ask them. You then use the sample to estimate the number of students who like the service. This is an example of estimating parameters about a population.
so in 1961, John Tukey, a prominent mathematician and a statistician, coined the term Exploratory Data Analysis (EDA). That is a process of analyzing data sets for seeing what the data can tell us beyond the formal modeling or hypothesis testing task. a process, where the hypothesis can be suggested by the data itself, not just using the data to confirm or reject a hypothesis suggested by the researcher.
The basic goals or EDA are:
- remove or correct erroneous data - data cleaning
- formulate initial hypotheses and draw on a few insights based on the initial investigations of the data.
- choose suitable analysis methods
For that we need to LOOK AT THE DATA - SEE THE DATA
For that we need:
- Statistics
- Data Cleaning techniques
- Data Visualizations
They'll all go hand in hand. Statistics will help you understand some insights about the data. That understanding and those insights will help us in data cleaning and I will show a few examples there. Also just looking at the Raw data may cause us to miss huge opportunities and insights in the data. The Raw data and the statistics by them selves can deceiving sometimes. And Visualizing the data will help you in coming up with your initial hypothesis about the data and determine the appropriate analysis methods and models. Sometimes even, visualization will help you in data cleaning and data understanding as you'll see statistics can be deceiving sometimes.
This is an iterative process Remember, the data analysis process is not linear, it is an iterative, incremental process; we don't collect data, then clean the data, then analyze the data. Instead this all happens in iterations; we collect the data, and do some initial analysis, based on which we clean the data, then do some more analysis, then maybe we then realize we don't have enough data for the analysis so we go back and collect some more and so on and so forth.
I say this because I want to emphasize that EDA is not a one-time thing. and because many of the topics we will cover in this module are topics that we'll keep coming back to again and again throughout the course, with more information.
But before we do any of that, we need to start with a tidy data. and that will be out topic for the next video.
Tidy Data and Data structures
Happy families are all alike; every unhappy family is unhappy in its own way
Leo Tolstoy
That's how Leo Tolstoy started his Anna Karenina Novel. So how does it relate to us here in data analysis?
Well it turns out, that we have some defined characteristics of what would be deemed as tidy data for example in Rectangular Data Structures:
- Every variable/attribute/feature forms a column
- Every observation forms a row
- Every type of observational unit forms a table
But if we think about what could be considered an untidy table, there's too many possibilities
- you could have those merged rows that act as separators
- You could have tally rows
- You could have column headers that are actually a table description
All of these are issues we have to tidy up before we can start with our analysis.
But Data generally don't come in this structured state: text and images for example, they first need to be processed and manipulated so that it can be represented as a set of features in tabular structure.
Let's take an picture example, at the end of the day, pictures are just pixels. where every pixel has an attribute of RGB, for colored pictures, and maybe on and off for black and white pictures.
If we wanted to represent this image in rectangular data structure/a data frame: and Let's assume that 0 means white, 1 means red, we can have this table here. However would this fit the description as tidy data?
Well, no, rows and columns here basically a matrix, you'd want to convert that to table that has X, Y, and is_red as columns.
Table structured data is only one common forms of structured data; by no means we're saying it's only one.; what would be tidy for one analysis project may not be for another. For example, spatial data, which are used in mapping and location analytics. Or graph and network data that are used to analyze relations between entities like social network relations.
so by no means we're saying that rectangular data structures are the only acceptable forms of structured data for analysis. Depending on your project, you'll want to choose the right form for your data.
What we've done here; converting this image or this raw source of information into a dataset is what's called data wrangling. Converting this image to a dataset, parsing server log files to analyze web application traffic. In constructing the dataset, we also define the data types for each of the features.
So looking at these 2 examples, you could see 2 different data types: Numerical and Categorical
Let's talk about that in the next video.
Data Types
There are 2 basic types of structured data:
- Numerical
- Continuous
- Discrete
- Categorical
- Ordinal
- Nominal
Numerical values can be continuous, as it taking any value in an interval, like height, weight, and temperature; you can have 30.345 inches, 150.57 pounds, and 98.6 degrees Fahrenheit. Or discrete; data that can only take integer values like number of children, number of cars, and number of pets. you can't have 1.5 children, 2.5 cars, or 1.5 pets.
and the other type of data is categorical: These are data that can only take specific set of values, representing possible categories.
For example, genders, and countries of athletes, rating scales on customer satisfaction surveys, letter grades of students in a class. Categorical data are split into nominal data, theses are just labels, or ordinal data, where the order matters or carries a meaning. Letter Grades, A is better then B which is better than a C, a rating scale of 5 is better than one. However, the white color is not better then blue, that's ordinal data.
Why do we care?
Why do we care about data types? Well, it's important to know what type of data you're dealing with, because different types of data require different types of analysis. You have to analyze continuous data differently than categorical data otherwise it would result in a wrong analysis.
Let's remember a few key terms of summary statistics, you may recall that we have 2 types of summary statistics:
- Central tendency measures: mean, median, mode
- and Dispersion measures: variance, standard deviation, range
For now, let's just focus on the central tendency measures, and let's look at the difference between mean and mode.
- Mean or the average: the sum of all the values divided by the number of values.
- Mode: the most commonly occurring category or value in data set. - which only makes sense for categorical data.
So it's obvious that the mean is a summary statistic for continuous data, but the mode is a summary statistic for categorical data. For a dataset of olympics athletes, you can get the mean of their ages, the mean of their heights, the mean of their weights, for example. It doesn't make sense to take the get the mean of their nationalities, of their sex. but you can get the mode of that.
Correctly computing Central Tendency measures becomes especially important when working on data cleaning and handling missing data as we'll talk about later.
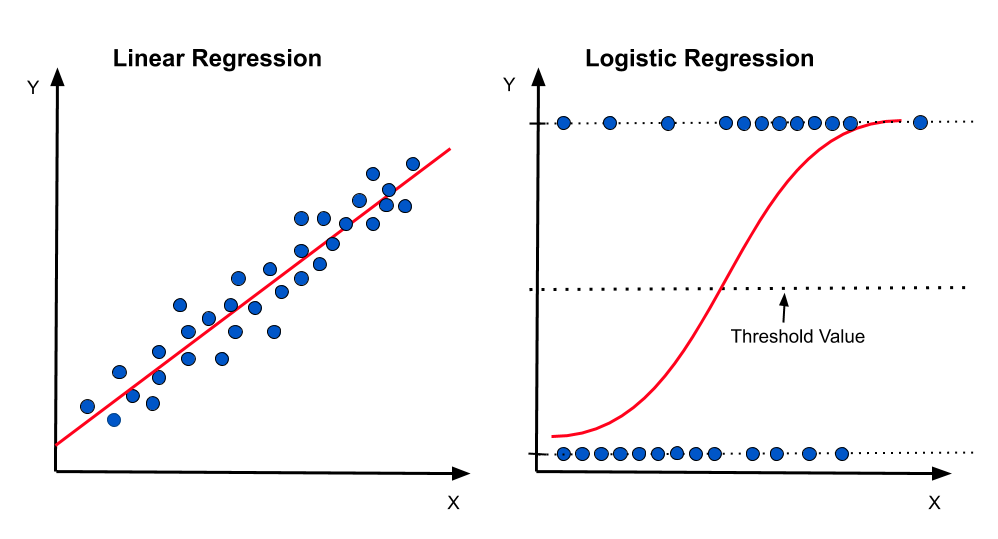
Another example for why we care about data types is when we're talking about data visualization. Categorical data can be visualized using bar charts, pie charts, histograms, and so on. Continuous data can be visualized using line charts, scatter plots, and so on.
Also, when we're talking about data modeling and predictive analysis, we'll talk more about that later in the course, if you're trying to predict a continuous value like the price of a house, you'll use a regression model. You'd use a logistical regression model if you're trying to predict predict whether a political candidate will win or lose an election, or a classification model if you're trying to predict whether a customer will buy a product or not.
import pandas as pd
# read_table and read_csv are the same except for the default delimiter
auto_mpg_df = pd.read_table('./data/auto-mpg/auto-mpg.data', sep="\t", header=None, names=('mpg', 'cylinders','displacement','horsepower','weight','acceleration','model_year','origin','car_name'))
#df.head() gets the first 5 rows, sample(5) gets 5 random rows
auto_mpg_df.sample(n=5)
| mpg | cylinders | displacement | horsepower | weight | acceleration | model_year | origin | car_name | |
|---|---|---|---|---|---|---|---|---|---|
| 114 | 12.0 | 8.0 | 350.0 | 180.0 | 4499.0 | 12.5 | 73.0 | 1.0 | oldsmobile vista cruiser |
| 40 | 19.0 | 6.0 | 232.0 | 100.0 | 2634.0 | 13.0 | 71.0 | 1.0 | amc gremlin |
| 247 | 30.0 | 4.0 | 97.0 | 67.0 | 1985.0 | 16.4 | 77.0 | 3.0 | subaru dl |
| 106 | 16.0 | 6.0 | 250.0 | 100.0 | 3278.0 | 18.0 | 73.0 | 1.0 | chevrolet nova custom |
| 179 | 24.0 | 4.0 | 134.0 | 96.0 | 2702.0 | 13.5 | 75.0 | 3.0 | toyota corona |
# df.info() gives a summary about the data: number of rows, number of columns, column names, data types, number of non-null values
auto_mpg_df.info()
# df.describe() gives statistical summaries of the data
auto_mpg_df.describe()
| mpg | cylinders | displacement | horsepower | weight | acceleration | model_year | origin | |
|---|---|---|---|---|---|---|---|---|
| count | 400.000000 | 409.000000 | 409.000000 | 403.000000 | 409.000000 | 409.000000 | 409.000000 | 409.000000 |
| mean | 23.482000 | 5.488998 | 195.759169 | 105.429280 | 2986.088020 | 15.496577 | 75.897311 | 1.564792 |
| std | 7.810255 | 1.715129 | 106.809049 | 38.959819 | 848.259456 | 2.812496 | 3.754633 | 0.796027 |
| min | 9.000000 | 3.000000 | 4.000000 | 46.000000 | 1613.000000 | 8.000000 | 70.000000 | 1.000000 |
| 25% | 17.375000 | 4.000000 | 105.000000 | 76.000000 | 2228.000000 | 13.600000 | 73.000000 | 1.000000 |
| 50% | 23.000000 | 4.000000 | 151.000000 | 95.000000 | 2833.000000 | 15.500000 | 76.000000 | 1.000000 |
| 75% | 29.000000 | 8.000000 | 302.000000 | 130.000000 | 3630.000000 | 17.100000 | 79.000000 | 2.000000 |
| max | 46.600000 | 8.000000 | 502.000000 | 230.000000 | 5140.000000 | 24.800000 | 82.000000 | 3.000000 |
Just looking at the info and the sample data, we could already see a few issues:
- the origin column is actually a categorical field not a numerical one.
- Also looking at the stats for it: count, min, max, ... it looks like it can't only carry a value of 1, 2, or 3.
- We can look at the data, and replace it with origin names, like US, Europe, and Asia.
- The model_year column is actually a You tell me in the quiz
- The cylinders column is a continuous numerical data, but it is actually a You tell me in the quiz
So not only are we doing data transformation, we're also doing some data wrangling and cleaning here.
# The decimal point will be confusion to someone seeing the data
auto_mpg_df['origin'] = auto_mpg_df['origin'].astype(int)
# Make Origin a categorical variable
auto_mpg_df['origin'] = pd.Categorical(auto_mpg_df.origin)
auto_mpg_df.info()
# Assuming for my analysis project, I want cylinders to be a numerical variable. In that case, it would be better to be a discrete variable
auto_mpg_df['cylinders'] = auto_mpg_df['cylinders'].astype('int')
auto_mpg_df.info()
# <Was that a good decision?>
# right now, model year is a to be a numerical field, and we realized that it's represented as values of 70, 71, 72, etc. If we want to add cars from the yar 2022, this column would be very confusing. and we so wee need to change those value by adding 1900 to each value.
# Please keep in mind, I'm confirming or denying the assumption that model year is a numerical variable. <You'll tell me that in the quiz>
auto_mpg_df['model_year'] = auto_mpg_df['model_year'] + 1900
auto_mpg_df
# Also you could do:
# auto_mpg_df['model_year'] = auto_mpg_df['model_year'].map(lambda x: x + 1900)
# OR
# auto_mpg_df['model_year'] = auto_mpg_df['model_year'].apply(lambda x: x + 1900)
| mpg | cylinders | displacement | horsepower | weight | acceleration | model_year | origin | car_name | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 18.0 | 8 | 307.0 | 130.0 | 3504.0 | 12.0 | 1970.0 | 1 | chevrolet chevelle malibu |
| 1 | 15.0 | 8 | 350.0 | 165.0 | 3693.0 | 11.5 | 1970.0 | 1 | buick skylark 320 |
| 2 | 18.0 | 8 | 318.0 | 150.0 | 3436.0 | 11.0 | 1970.0 | 1 | plymouth satellite |
| 3 | 16.0 | 8 | 304.0 | 150.0 | 3433.0 | 12.0 | 1970.0 | 1 | amc rebel sst |
| 4 | 17.0 | 8 | 302.0 | 140.0 | 3449.0 | 10.5 | 1970.0 | 1 | ford torino |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 404 | 27.0 | 4 | 140.0 | 86.0 | 2790.0 | 15.6 | 1982.0 | 1 | ford mustang gl |
| 405 | 44.0 | 4 | 97.0 | 52.0 | 2130.0 | 24.6 | 1982.0 | 2 | vw pickup |
| 406 | 32.0 | 4 | 135.0 | 84.0 | 2295.0 | 11.6 | 1982.0 | 1 | dodge rampage |
| 407 | 28.0 | 4 | 120.0 | 79.0 | 2625.0 | 18.6 | 1982.0 | 1 | ford ranger |
| 408 | 31.0 | 4 | 119.0 | 82.0 | 2720.0 | 19.4 | 1982.0 | 1 | chevy s-10 |
409 rows × 9 columns
auto_mpg_df.info()
# Merge the 2 dataframes, when you already have the another dataframe; I already showed this in a pervious notebook, so i won't run it.
# origins_df = pd.read_csv('./data/auto-mpg/origin.csv');
# auto_mpg_df = pd.merge(auto_mpg_df, origins_df, on='origin')
# auto_mpg_df.sample(5)
auto_mpg_df['origin_spelled'] = auto_mpg_df['origin'].astype(str).map({'1':'US', '2':'European', '3': 'Asian'})
auto_mpg_df.info()
you will learn a lot more about this topic the more you work with data. But for now, you know the data types, we do we care about them, and how to tidy up your data to move on with the analysis.
Data Cleaning
Now that we know about the data types we have in our data, we can start cleaning our data. Data cleaning is the process of fixing or removing incorrect, corrupted, incorrectly formatted, duplicate, or incomplete data within a dataset.
We start we a tidy dataset, we examine it, investigate it, and do some corrective actions to it, and and we end up with a clean dataset. So what sorts of of issues do we clean up? Well, there's a lot of them, Like Leo Tolstoy mentioned, every family is unhappy in its own way, so every dataset is dirty in its own way. but we'll focus on the most common ones:
- Duplicate data
- Missing data
- Anomalies and outliers
Duplicate Data
Let's start with duplicate data. Duplicate data is data that has been entered more than once. For example, if you have a dataset of customers, and you have a customer that has been entered twice, or more than twice, that's duplicate data. Or maybe you have a customer who filled out the same survey twice. That's duplicate data.
Duplicate data is a problem because it can skew your analysis, give the false impression that there's more data than there actually is. So how do we deal with duplicate data? Well, we can remove it, or we can keep it. If you have a dataset of customers, and you have a customer that has been entered twice, you can remove one of them or merge the records, or you can keep them both. It depends on the situation. In a huge dataset, a few duplicate records, may not do much. But if you're merging the data with another, that could cause problems. It really depends on your project and the problem space you're working on.
So let's see how we can find and handle duplicate records.
# this returns a series of booleans. You can pass some conditions to the functions, as to what needs to be considered in the comparison, and which record to be marked.
auto_mpg_df.duplicated()
# Because it's truncated for display, we can get the summation
auto_mpg_df.duplicated().sum()
# We can also filter the dataframe based on the results of the duplicated function
auto_mpg_df[auto_mpg_df.duplicated()]
| mpg | cylinders | displacement | horsepower | weight | acceleration | model_year | origin | car_name | origin_spelled | |
|---|---|---|---|---|---|---|---|---|---|---|
| 255 | NaN | 8 | 383.0 | 175.0 | 4166.0 | 10.5 | 1970.0 | 1 | plymouth satellite (sw) | US |
| 393 | 16.0 | 8 | 400.0 | 180.0 | 4220.0 | 11.1 | 1977.0 | 1 | pontiac grand prix lj | US |
# Filter out the duplicates from the dataframe based on the results of the duplicated function
auto_mpg_without_duplicates1 = auto_mpg_df[~auto_mpg_df.duplicated()]
# Let's check now?
auto_mpg_without_duplicates1.duplicated().sum()
# we didn't change the original dataframe, to do that, use the
auto_mpg_df.duplicated().sum()
auto_mpg_without_duplicates2 = auto_mpg_df.drop_duplicates()
# Let's check now?
auto_mpg_without_duplicates2.duplicated().sum()
# to change the original dataframe, use the inplace parameter
auto_mpg_df.drop_duplicates(inplace=True)
# OR
# auto_mpg_df = auto_mpg_df.drop_duplicates()
auto_mpg_df.info()
Missing Data, Anamolies, and Outliers
In working with data, you will have to deal with missing data, anomalies, and outliers.
Missing data is when you have a record, with a number of properties and some of those property values are missing. Maybe even values are are clearly incorrect. Like an age field of 0. Anomalies and outliers are for example when you have a record that seems incorrect, but may actually be true. Like, if I tell you that Bangladesh, the country that is slightly bigger than the state of New York, has a more people than Russia. That's an anomaly, but it's true. Or maybe you have a record of a person who's 5 feet tall, and weighs 300 pounds. That's an outlier, but could be true. and sometime you'll have to ask yourself the question: Is this an outlier or an anamoly that would mess up or skew your result, or is it a key finding or key observation.
or so how we handle those data issues: you could remove the records altogether, or you could substitute the data with some other value. Your project is what would determine the right approach here.
Also, This other value needs to fit within the dataset, not cause issues itself. It shouldn't skew the results itself. so what would this value be?
- Handling of Missing data
- Do you remove those records altogether, do you substitute those missing data with some other value
- what would that value be? We need what we call a typical value?
- Do you remove those records altogether, do you substitute those missing data with some other value
This is where Statistics comes to the rescue once more. Central tendency measures along with some data visualizations would help us find those values. Depending on the type of the data, we could replace the data with the mean or the mode. In some cases, the median could make more sense to use as well.
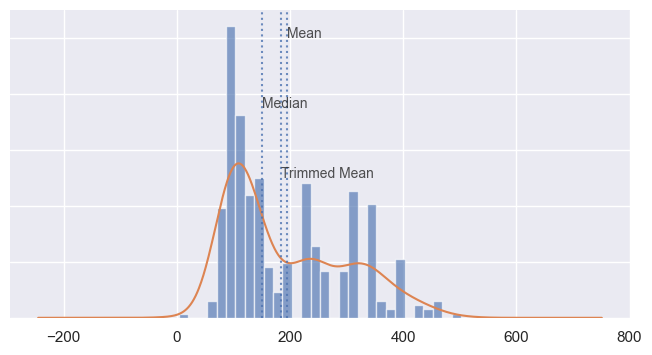
There are different variations of the mean values that we can compute: We already talked about the normal mean, but I also want to introduce you to the another variation here, the trimmed mean. This is when you calculate it by dropping a fixed number of sorted values at each end and then taking an average of the remaining values. A trimmed mean eliminates the influence of extreme values. For example, in international diving the top score and bottom score from five judges are dropped, and the final score is the average of the scores from the three remaining judges. This makes it difficult for a single judge to manipulate the score, perhaps to favor their country’s contestant.
In some cases, using the median would be a better choice. The median is the middle number on a sorted list of the data. Compared to the mean, which uses all observations, the median depends only on the values in the center of the sorted data. Let’s say we want to look at typical household incomes in neighborhoods around Lake Washington in Seattle. In comparing the Medina neighborhood to the Windermere neighborhood, using the mean would produce very different results because Bill Gates lives in Medina. If we use the median, it won’t matter how rich Bill Gates is—the position of the middle observation will remain the same. and the median here would be more representative of the typical value.
The median is not influenced by outliers, so it's a more robust estimate of location.
You should be able to use simple pandas operations to substitute those values.
But let's see how we can get those values in the first place.
auto_mpg_df.describe()
| mpg | cylinders | displacement | horsepower | weight | acceleration | model_year | |
|---|---|---|---|---|---|---|---|
| count | 399.000000 | 407.000000 | 407.000000 | 401.000000 | 407.000000 | 407.000000 | 407.000000 |
| mean | 23.500752 | 5.476658 | 194.797297 | 105.069825 | 2980.157248 | 15.519656 | 1975.909091 |
| std | 7.811039 | 1.710247 | 106.180724 | 38.721120 | 846.093527 | 2.799904 | 3.752056 |
| min | 9.000000 | 3.000000 | 4.000000 | 46.000000 | 1613.000000 | 8.000000 | 1970.000000 |
| 25% | 17.500000 | 4.000000 | 104.500000 | 76.000000 | 2227.000000 | 13.700000 | 1973.000000 |
| 50% | 23.000000 | 4.000000 | 151.000000 | 95.000000 | 2830.000000 | 15.500000 | 1976.000000 |
| 75% | 29.000000 | 8.000000 | 302.000000 | 130.000000 | 3616.500000 | 17.150000 | 1979.000000 |
| max | 46.600000 | 8.000000 | 502.000000 | 230.000000 | 5140.000000 | 24.800000 | 1982.000000 |
from scipy.stats import trim_mean
auto_displacement_mean = auto_mpg_df['displacement'].mean()
auto_displacement_trimmed_mean = trim_mean(auto_mpg_df['displacement'], 0.1)
auto_displacement_median = auto_mpg_df['displacement'].median()
print("mean is {}, trimmed mean is {}, median is {}".format(auto_displacement_mean, auto_displacement_trimmed_mean, auto_displacement_median))
Next we need to find the missing fields and decide how we want to handle them
# Find the missing data
auto_mpg_df.isnull().sum()
# Looks like we have 8 missing values in the mpg column and 6 missing values in the horsepower column
# Let's see what those rows look like
auto_mpg_df[auto_mpg_df['mpg'].isnull()]
| mpg | cylinders | displacement | horsepower | weight | acceleration | model_year | origin | car_name | origin_spelled | |
|---|---|---|---|---|---|---|---|---|---|---|
| 10 | NaN | 4 | 133.0 | 115.0 | 3090.0 | 17.5 | 1970.0 | 2 | citroen ds-21 pallas | European |
| 11 | NaN | 8 | 350.0 | 165.0 | 4142.0 | 11.5 | 1970.0 | 1 | chevrolet chevelle concours (sw) | US |
| 12 | NaN | 8 | 351.0 | 153.0 | 4034.0 | 11.0 | 1970.0 | 1 | ford torino (sw) | US |
| 13 | NaN | 8 | 383.0 | 175.0 | 4166.0 | 10.5 | 1970.0 | 1 | plymouth satellite (sw) | US |
| 14 | NaN | 8 | 360.0 | 175.0 | 3850.0 | 11.0 | 1970.0 | 1 | amc rebel sst (sw) | US |
| 17 | NaN | 8 | 302.0 | 140.0 | 3353.0 | 8.0 | 1970.0 | 1 | ford mustang boss 302 | US |
| 39 | NaN | 4 | 97.0 | 48.0 | 1978.0 | 20.0 | 1971.0 | 2 | volkswagen super beetle 117 | European |
| 369 | NaN | 4 | 121.0 | 110.0 | 2800.0 | 15.4 | 1981.0 | 2 | saab 900s | European |
# Assuming the analytics project here involves a step to predict the mpg of a car, we can't use these rows. So we'll drop them
auto_mpg_df.dropna(subset=['mpg'], inplace=True)
#Then we confirm that we don't have any missing values in the mpg column
auto_mpg_df.isnull().sum()
For the horsepower, and before we decide how to handle it, we need to calculate the central tendency measures and and visualize it to see if we can find any patterns or anomalies in it. and to determine what would be the better central tendency measure to use to replace the missing values.
auto_mpg_df['displacement'].describe()
import matplotlib as mpl
import matplotlib.pyplot as plt
# plt.style.use("bmh")
fig, ax = plt.subplots(figsize = (8,4))
auto_mpg_df['displacement'].plot(kind="hist", density= True, bins=30, alpha = 0.65)
auto_mpg_df['displacement'].plot(kind="kde")
ax.axvline(auto_displacement_mean, alpha = 0.8, linestyle = ":")
ax.axvline(auto_displacement_median, alpha = 0.8, linestyle = ":")
ax.axvline(auto_displacement_trimmed_mean, alpha = 0.8, linestyle = ":")
ax.set_ylim(0, .011)
ax.set_yticklabels([])
ax.set_ylabel("")
ax.text(auto_displacement_mean-.1, .01, "Mean", size = 10, alpha = 0.8)
ax.text(auto_displacement_median-.4, .0075, "Median", size = 10, alpha = 0.8)
ax.text(auto_displacement_trimmed_mean+.4, .0050, "Trimmed Mean", size = 10, alpha = 0.8)
ax.tick_params(left = False, bottom = False)
for ax, spine in ax.spines.items():
spine.set_visible(False)
plt.show()
# We can can then use those values to substitute the missing data. so we'll use the median value to fill the missing values in the horsepower column
auto_mpg_df['horsepower'].fillna(auto_mpg_df['horsepower'].median(), inplace=True)
auto_mpg_df.isnull().sum()
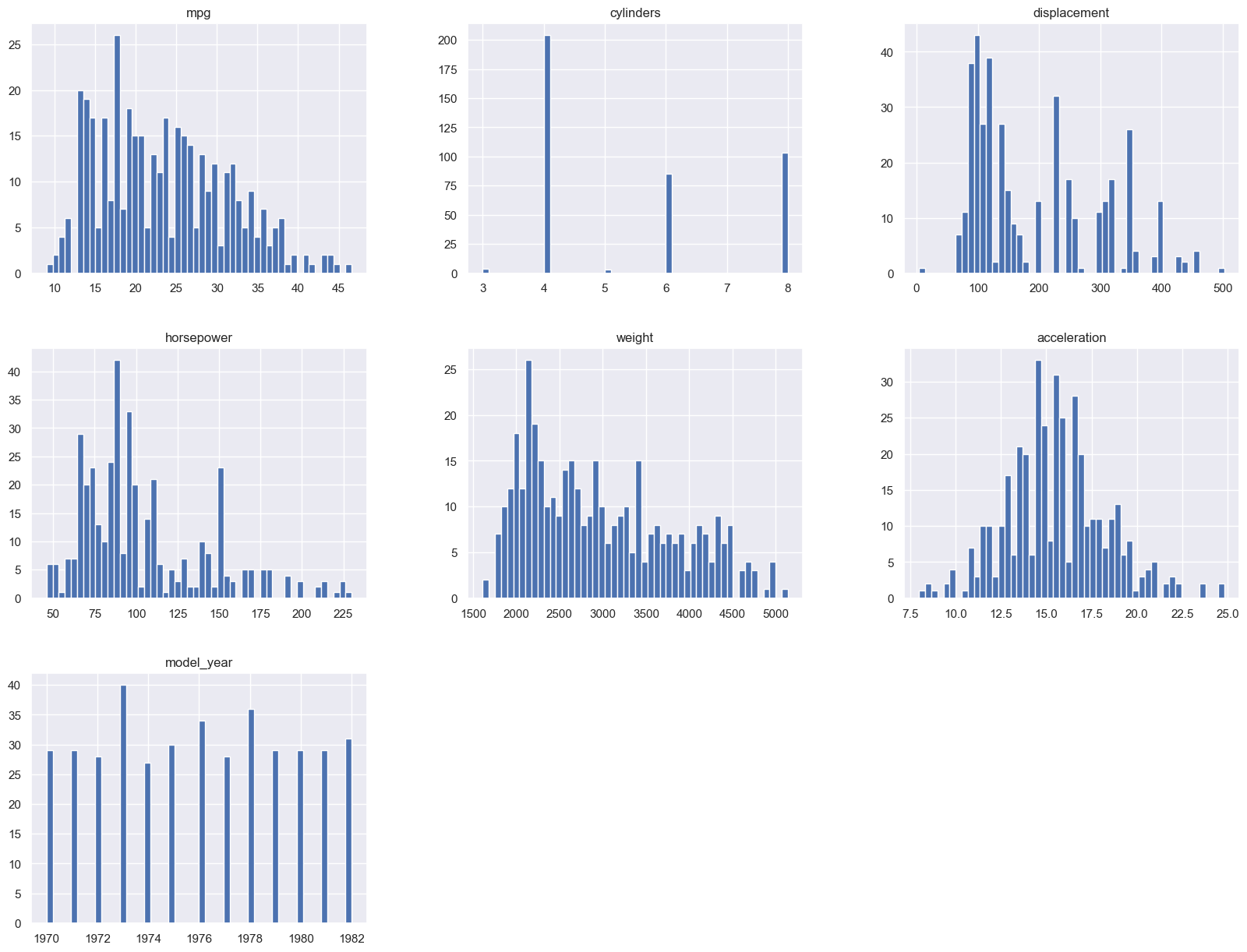
You could also see a visual of all the features histograms in one plot, to see if there are any patterns or anomalies in the data, see the frequency of the values for categorical data, and where the the majority of the data is located for the numerical data.
import matplotlib as mpl
import matplotlib.pyplot as plt
auto_mpg_df.hist(bins=50, figsize=(20,15))
plt.show()
You could employ similar techniques to deal with outliers and anomalies. You could remove them, or you could replace them with some other value. But you need to be careful here, because you don't want to replace them with a value that would skew the results. Or you if your analysis is about finding the most performant cars, then you may want to keep those outliers in the dataset. In that case they're be considered key observations. We use other statistical concepts from statistics to deal with outliers and anomalies, namely measures of variability and data distribution: standard deviation, variances, percentiles.
Please make sure you do the reading and the exercises for this section. It's very important to understand the concepts here.
## On outliers, here's how we can detect them
auto_mpg_df['displacement'].plot(kind="box")
<AxesSubplot: >
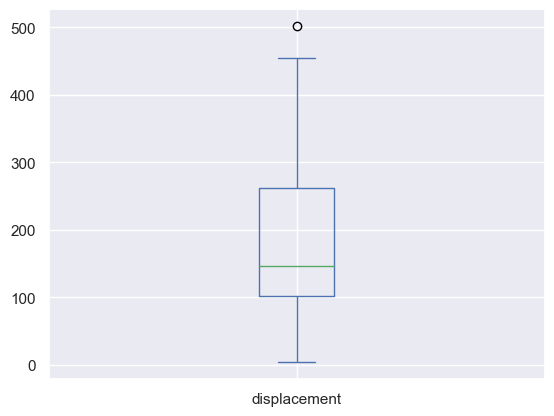
# Once you have the box plot, you can use the whiskers to determine the outliers.
# The whiskers are the lines that extend from the box. The top whisker is the 75th percentile, and the bottom whisker is the 25th percentile.
# The outliers are the points that are outside the whiskers.
# We can also use the describe function to get the 25th and 75th percentile
auto_mpg_df['displacement'].describe()
# We can also use the quantile function to get the 25th and 75th percentile
auto_mpg_df['displacement'].quantile([0.25, 0.75])
# We can also use the IQR function to get the 25th and 75th percentile
Q1 = auto_mpg_df['displacement'].quantile(0.25)
Q3 = auto_mpg_df['displacement'].quantile(0.75)
print("Q1 is {} and Q3 is {}".format(Q1, Q3))
IQR = Q3 - Q1
print("IQR is {}".format(IQR))
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
print("The lower bound is {}, and the upper bound is {}".format(lower_bound, upper_bound))
## Records where the displacement values are outside the lower and upper bounds are outliers
auto_mpg_df[(auto_mpg_df['displacement'] < lower_bound) | (auto_mpg_df['displacement'] > upper_bound)]
# That record doesn't look like a real data, so we'll drop it
auto_mpg_df.drop(auto_mpg_df[(auto_mpg_df['displacement'] < lower_bound) | (auto_mpg_df['displacement'] > upper_bound)].index, inplace=True)
About Statistical Analysis
In this video we lightly touched on so many topics.
Data Visualization
I've mentioned to you before that for you do a good EDA, you need to LOOK AT THE DATA - SEE THE DATA - UNDERSTAND THE DATA
Statistical analysis is very important for EDA and descriptive analysis, but it's not the only thing you need to do. In fact, depending solely on statistical analysis can lead to wrong conclusions, and wrong analysis. It could lead to wrong data cleaning, and wrong data modeling. and we've seen how visualizations can help us in understanding the data. and cleaning it.
Let's take a look at this dataset:
import pandas as pd
datasaurus = pd.read_table("./data/datasaurus.tsv")
datasaurus.head(5)
| dataset | x | y | |
|---|---|---|---|
| 0 | dino | 55.3846 | 97.1795 |
| 1 | dino | 51.5385 | 96.0256 |
| 2 | dino | 46.1538 | 94.4872 |
| 3 | dino | 42.8205 | 91.4103 |
| 4 | dino | 40.7692 | 88.3333 |
# Split the data into multiple dataframes
dino_df = datasaurus[datasaurus["dataset"] == "dino"]
away_df = datasaurus[datasaurus["dataset"] == "away"]
h_lines_df = datasaurus[datasaurus["dataset"] == "h_lines"]
v_lines_df = datasaurus[datasaurus["dataset"] == "v_lines"]
x_shape_df = datasaurus[datasaurus["dataset"] == "x_shape"]
star_df = datasaurus[datasaurus["dataset"] == "star"]
high_lines_df = datasaurus[datasaurus["dataset"] == "high_lines"]
circle_df = datasaurus[datasaurus["dataset"] == "circle"]
bullseye_df = datasaurus[datasaurus["dataset"] == "bullseye"]
dots_df = datasaurus[datasaurus["dataset"] == "dots"]
slant_up_df = datasaurus[datasaurus["dataset"] == "slant_up"]
slant_down_df = datasaurus[datasaurus["dataset"] == "slant_down"]
wide_lines_df = datasaurus[datasaurus["dataset"] == "wide_lines"]
print("\ndino_df")
print(dino_df.describe())
print("\naway_df")
print(away_df.describe())
print("\nh_lines_df")
print(h_lines_df.describe())
print("\nv_lines_df")
print(v_lines_df.describe())
import matplotlib.pyplot as plt
# import seaborn as sns
# sns.set()
plt.style.use("bmh")
fig, (
(ax1,ax2,ax3),
(ax4,ax5,ax6),
(ax7,ax8,ax9),
(ax10,ax11,ax12),
(ax13,ax14,ax15)
) = plt.subplots(5,3, figsize=(15, 15), sharex=True)
ax1.scatter(away_df["x"], away_df["y"])
ax1.set_title("away_df")
ax2.scatter(h_lines_df["x"], h_lines_df["y"])
ax2.set_title("h_lines_df")
ax3.scatter(v_lines_df["x"], v_lines_df["y"])
ax3.set_title("v_lines_df")
ax4.scatter(x_shape_df["x"], x_shape_df["y"])
ax4.set_title("x_shape_df")
ax5.scatter(star_df["x"], star_df["y"])
ax5.set_title("star_df")
ax6.scatter(high_lines_df["x"], high_lines_df["y"])
ax6.set_title("high_lines_df")
ax7.scatter(circle_df["x"], circle_df["y"])
ax7.set_title("circle_df")
ax8.scatter(bullseye_df["x"], bullseye_df["y"])
ax8.set_title("bullseye_df")
ax9.scatter(dots_df["x"], dots_df["y"])
ax9.set_title("dots_df")
ax10.scatter(slant_up_df["x"], slant_up_df["y"])
ax10.set_title("slant_up_df")
ax11.scatter(slant_down_df["x"], slant_down_df["y"])
ax11.set_title("slant_down_df")
ax12.scatter(wide_lines_df["x"], wide_lines_df["y"])
ax12.set_title("wide_lines_df")
ax13.scatter(dino_df["x"], dino_df["y"])
ax13.set_title("dino_df")
Text(0.5, 1.0, 'dino_df')

Data Correlations
Exploratory data analysis involves examining correlation among features or properties or the columns and a target variable.
Later on, you'll learn that in machine learning, the amount of data you have matters a lot, and the more features you use, your more rows of observation records you need to have. for the model to be able to learn about the patterns between the different features. One that that could help with that, is to find features that are highly correlated with each other, and remove one of them. This is called feature selection.
So what is correlation? Correlation is a statistical measure that indicates the extent to which two or more variables fluctuate together. It is used to identify the degree of relationship between two variables. The correlation coefficient is a statistical measure that indicates the strength of the relationship between two variables. It is a number between -1 and 1. A value of 1 indicates a perfect positive correlation, a value of -1 indicates a perfect negative correlation, and a value of 0 indicates no correlation at all. Correlation can be one of the measures used in inferential statistics to determine the strength of the relationship between two variables.
and as with everything in data science and data analysis, domain knowledge is needed to understand the results and not come up with bad conclusions.

corr_matrix = auto_mpg_df.corr()
corr_matrix
You could also get the correlation for a particular column. Let's say we want to see how the horsepower is correlated with the weight of the car. We could use the corr() method on the dataframe, and pass the column name as an argument to it.
corr_matrix["horsepower"].sort_values(ascending=False)
Data like this could aid in feature selection and can be used to determine removing one feature from the dataset to reduce the number of features, and thus the number of rows of data needed to train the model.
Looking at the data above here, it might be suggested that there's a high correlation between the horsepower and the weight of the car. But can you get rid of one and keep the other? With domain knowledge, you could learn that while there may be some correlation, it's not where if you need to increase the horsepower, you increase the weight. It's more of Because the weight is high, the horsepower needs to be high as well.
Domain knowledge could also dismiss that as a probable sampling issue where the data may not be representative of the population. There may be light cars with high horse power as well. So you can't just remove a feature because it's highly correlated with another feature.
Let me show you another way where you can see this correlation visually.
from pandas.plotting import scatter_matrix
attributes = ["mpg", "weight", "displacement",
"horsepower", "cylinders"]
scatter_matrix(auto_mpg_df[attributes], figsize=(12, 8))
array([[<AxesSubplot: xlabel='mpg', ylabel='mpg'>,
<AxesSubplot: xlabel='weight', ylabel='mpg'>,
<AxesSubplot: xlabel='displacement', ylabel='mpg'>,
<AxesSubplot: xlabel='horsepower', ylabel='mpg'>,
<AxesSubplot: xlabel='cylinders', ylabel='mpg'>],
[<AxesSubplot: xlabel='mpg', ylabel='weight'>,
<AxesSubplot: xlabel='weight', ylabel='weight'>,
<AxesSubplot: xlabel='displacement', ylabel='weight'>,
<AxesSubplot: xlabel='horsepower', ylabel='weight'>,
<AxesSubplot: xlabel='cylinders', ylabel='weight'>],
[<AxesSubplot: xlabel='mpg', ylabel='displacement'>,
<AxesSubplot: xlabel='weight', ylabel='displacement'>,
<AxesSubplot: xlabel='displacement', ylabel='displacement'>,
<AxesSubplot: xlabel='horsepower', ylabel='displacement'>,
<AxesSubplot: xlabel='cylinders', ylabel='displacement'>],
[<AxesSubplot: xlabel='mpg', ylabel='horsepower'>,
<AxesSubplot: xlabel='weight', ylabel='horsepower'>,
<AxesSubplot: xlabel='displacement', ylabel='horsepower'>,
<AxesSubplot: xlabel='horsepower', ylabel='horsepower'>,
<AxesSubplot: xlabel='cylinders', ylabel='horsepower'>],
[<AxesSubplot: xlabel='mpg', ylabel='cylinders'>,
<AxesSubplot: xlabel='weight', ylabel='cylinders'>,
<AxesSubplot: xlabel='displacement', ylabel='cylinders'>,
<AxesSubplot: xlabel='horsepower', ylabel='cylinders'>,
<AxesSubplot: xlabel='cylinders', ylabel='cylinders'>]],
dtype=object)
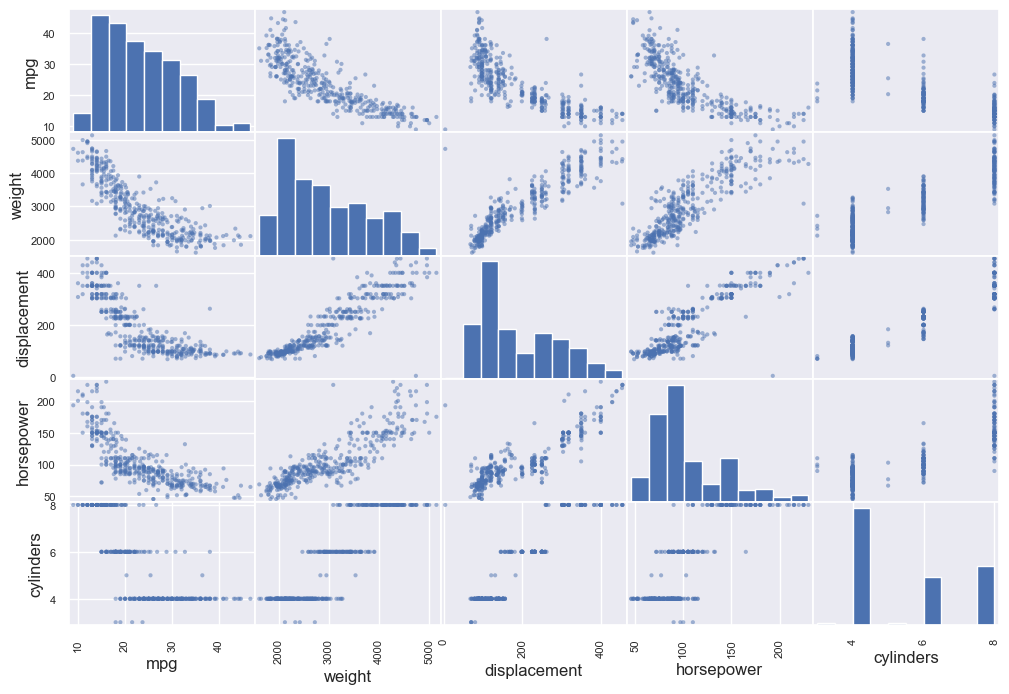
and from here you could see that the figure where the same property meets, is a histogram about the frequency of the data
https://courses.helsinki.fi/sites/default/files/course-material/4509270/IntroDS-03.pdf
Assignments
- Lab assignment on EDA
- For a particular problem set by me, what kinds of questions would you ask? what data sources would you use?